Error Handling
我们可以将错误处理配置拆解为三个核心部分:监控层 (onError/onCatch)、展示层 (errorComponent) 和 恢复机制。
1. 监控层:onError 与 onCatch
这两个属性主要用于“逻辑副作用”,即在错误发生时执行代码(如记录日志),而不是渲染 UI。
onError:- 触发时机:当路由的
beforeLoad或loader函数抛出错误时触发。 - 主要用途:用于生产环境的错误监控(如对接 Sentry、Datadog)或简单的调试日志。
- 特点:它是响应式的,每当加载失败时都会运行。
- 触发时机:当路由的
onCatch:- 主要用途:它类似于 React 的
componentDidCatch或try/catch块。它通常用于捕获那些你不希望通过errorComponent展示给用户,而是想在内部处理掉的异常。
- 主要用途:它类似于 React 的
2. 展示层:errorComponent
这是最重要的配置,它决定了当错误发生时,用户在界面上看到的内容。
局部隔离:
errorComponent会渲染在当前路由的<Outlet />位置。这意味着如果子路由报错,导航栏和侧边栏(父路由)仍然可以正常显示,不会导致全屏白屏。接收参数:该组件会自动接收到以下 Props:
error: 捕获到的错误对象。你可以通过error.message显示具体的错误信息。reset: 一个非常有用的函数。调用它会尝试重新执行当前路由的loader。info: 包含组件堆栈等调试信息。
3. 实现“点击重试”功能
利用 errorComponent 提供的 reset 参数,你可以让用户在网络波动失败后一键恢复,而不需要刷新整个网页。
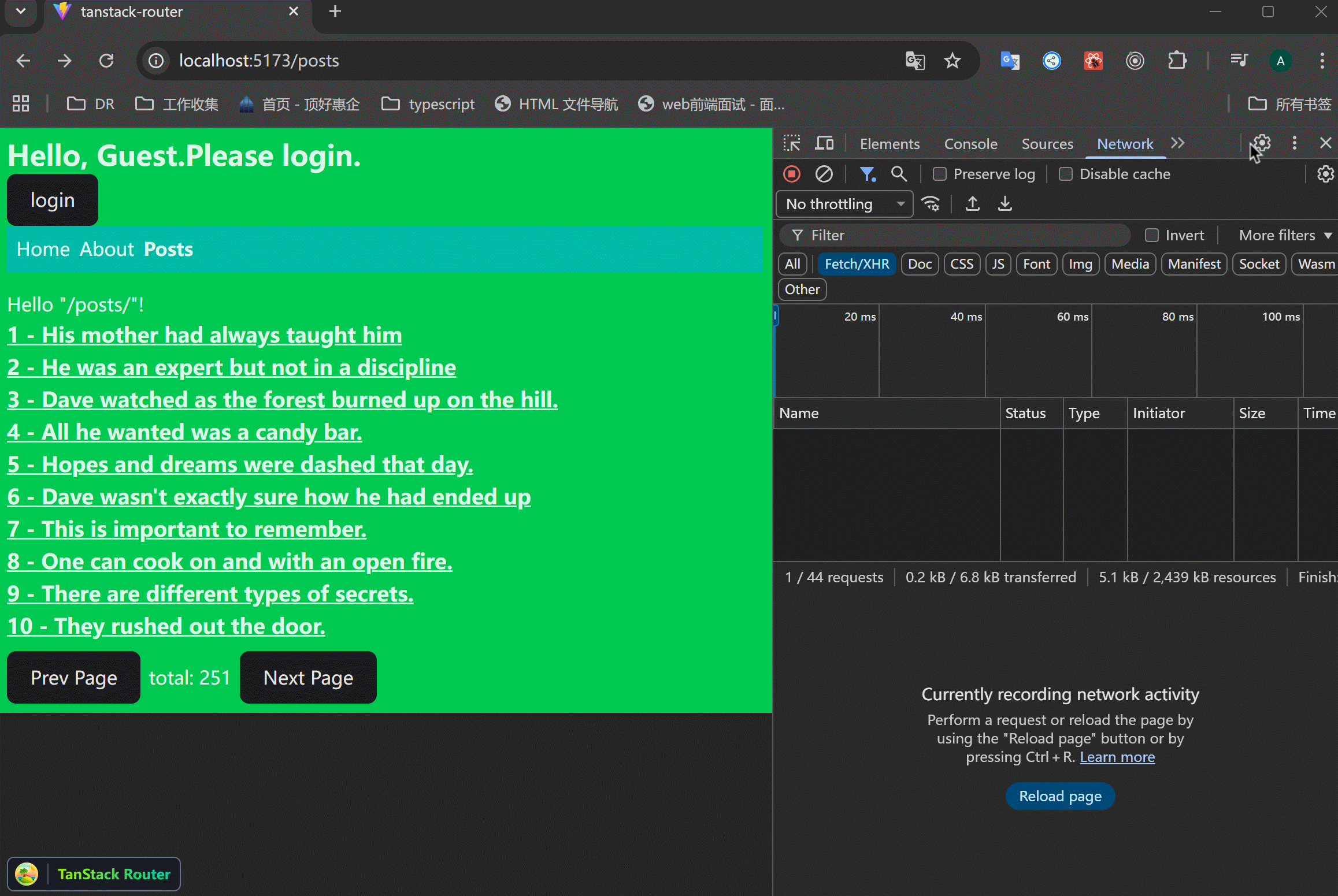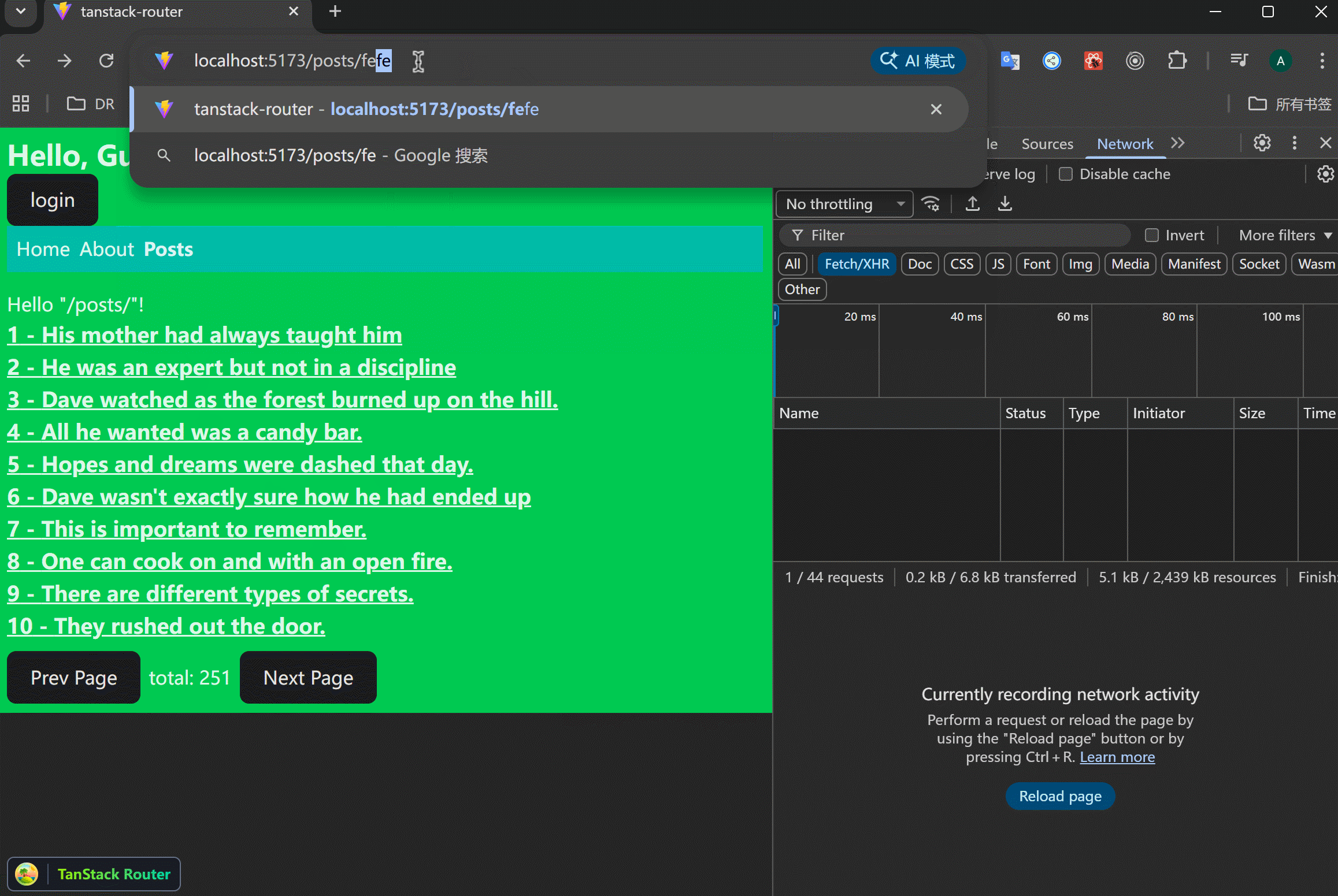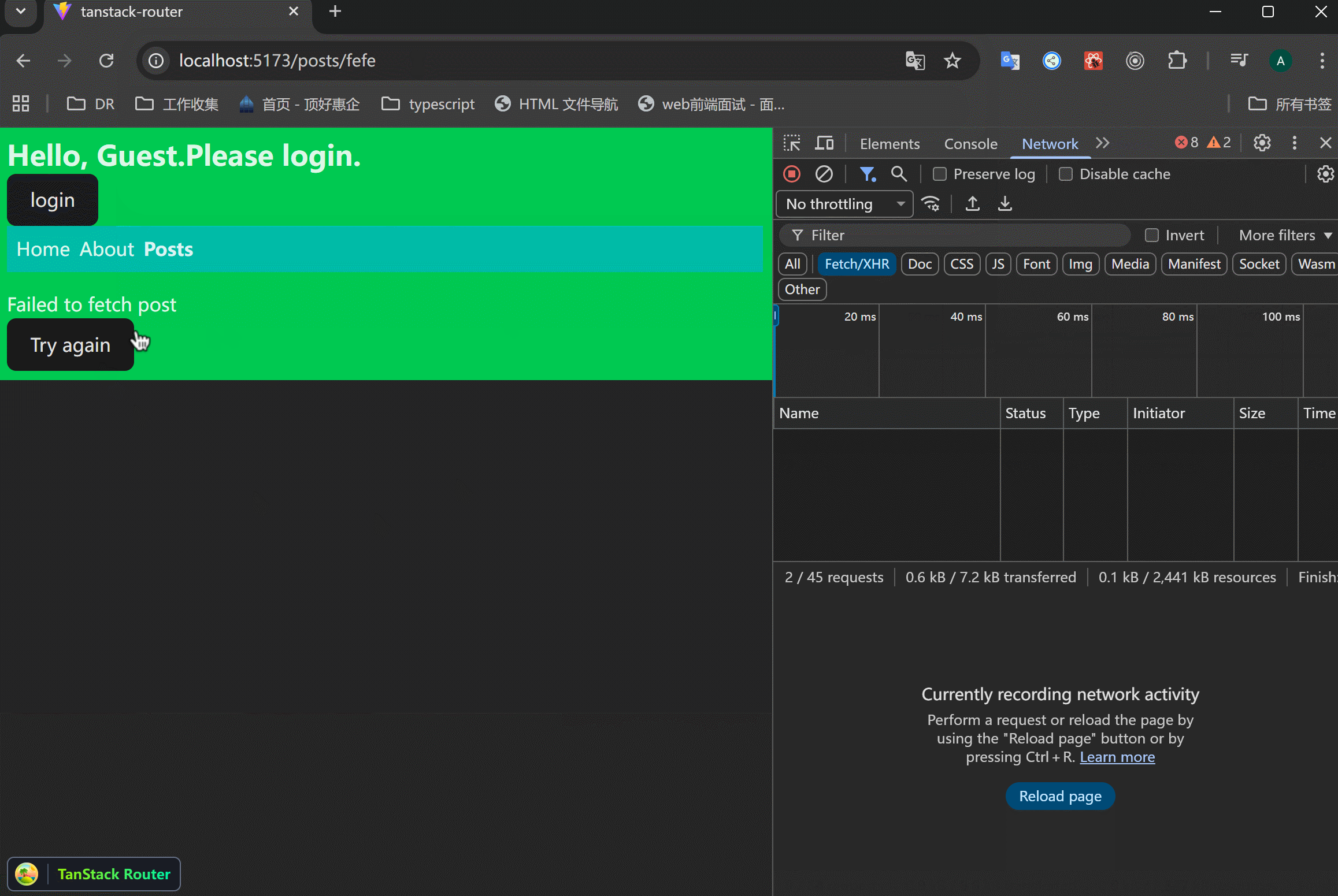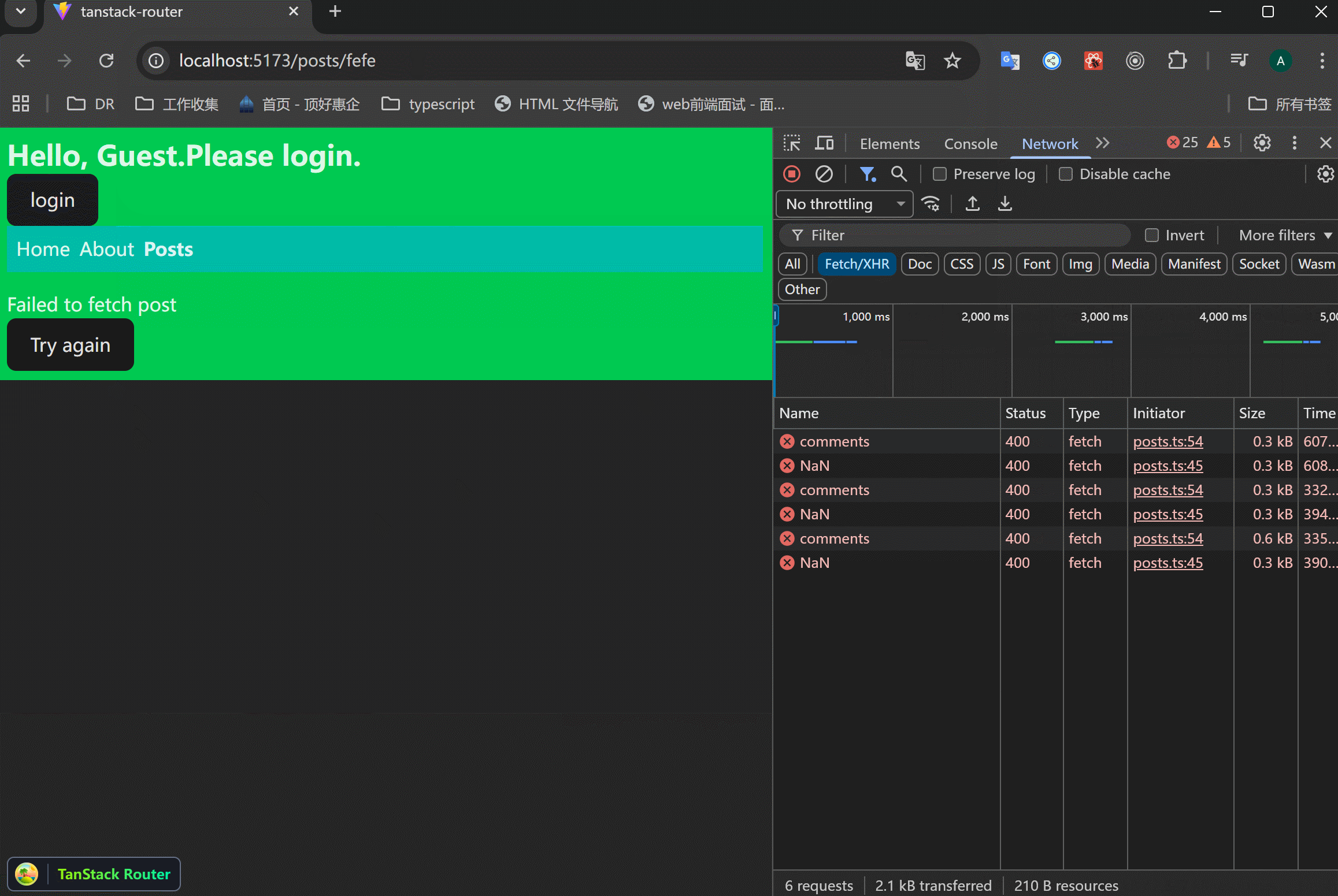
xxxxxxxxxx101errorComponent: ({ error, reset }) => {2 return (3 <div className="error-container">4 <h3>数据加载失败</h3>5 <p style={{ color: 'red' }}>{error.message}</p>6 {/* 调用 reset() 会重新触发当前路由的 loader */}7 <button onClick={() => reset()}>再试一次</button>8 </div>9 )10}老师案例
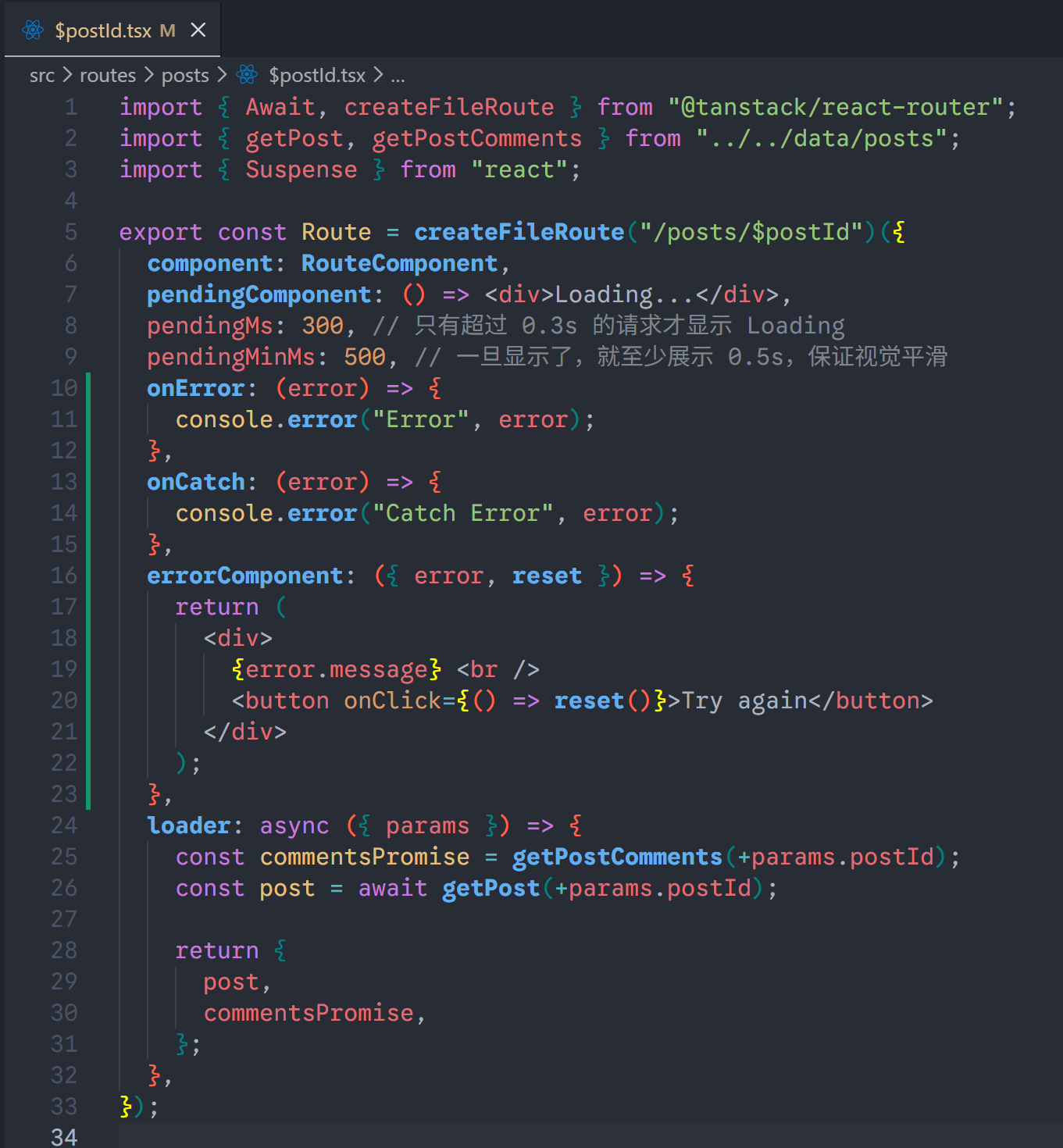
可以看到,errorComponent展示了,但是点击Try again按钮没有发起重新请求,这是因为reset并不会发起loader里面的请求。
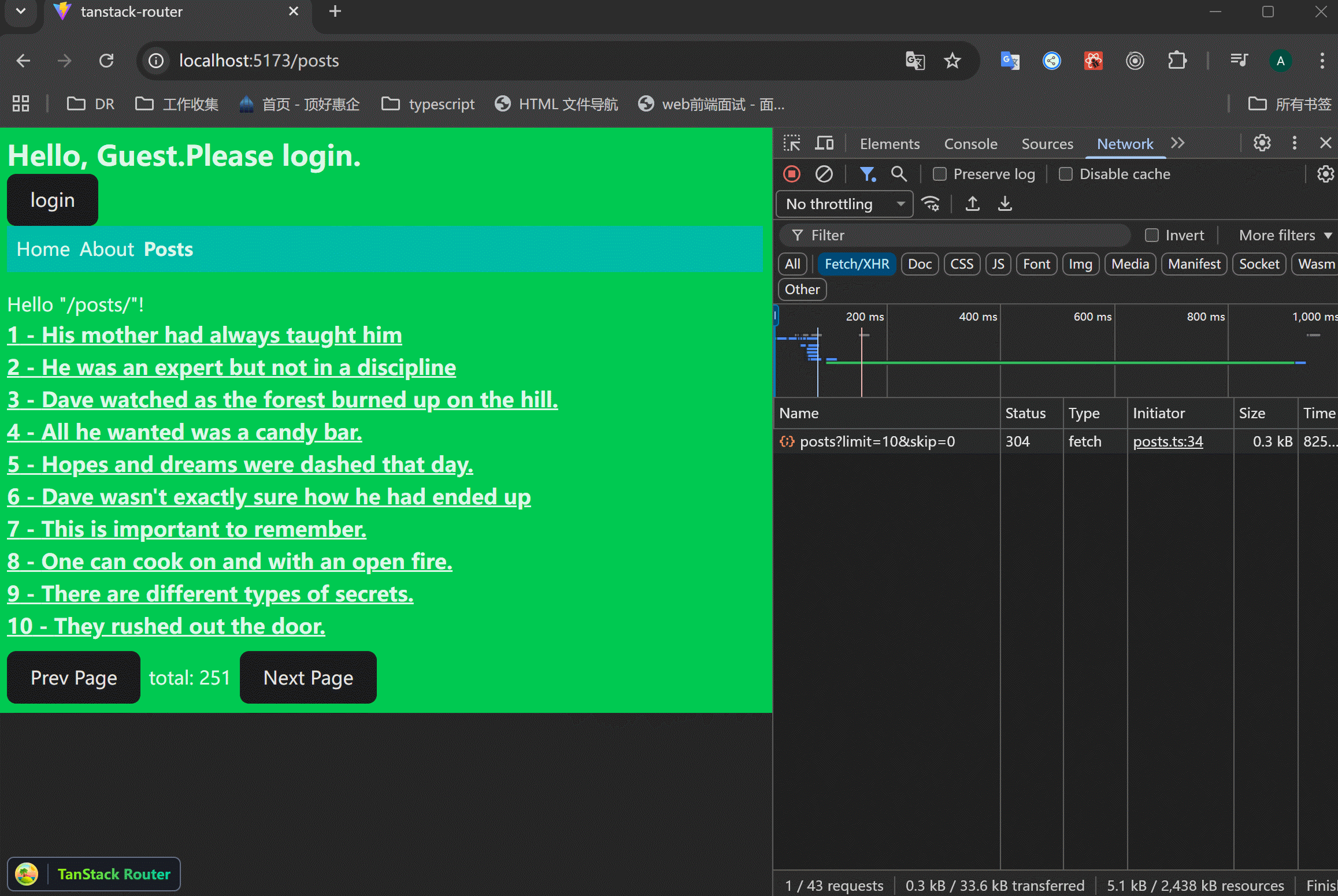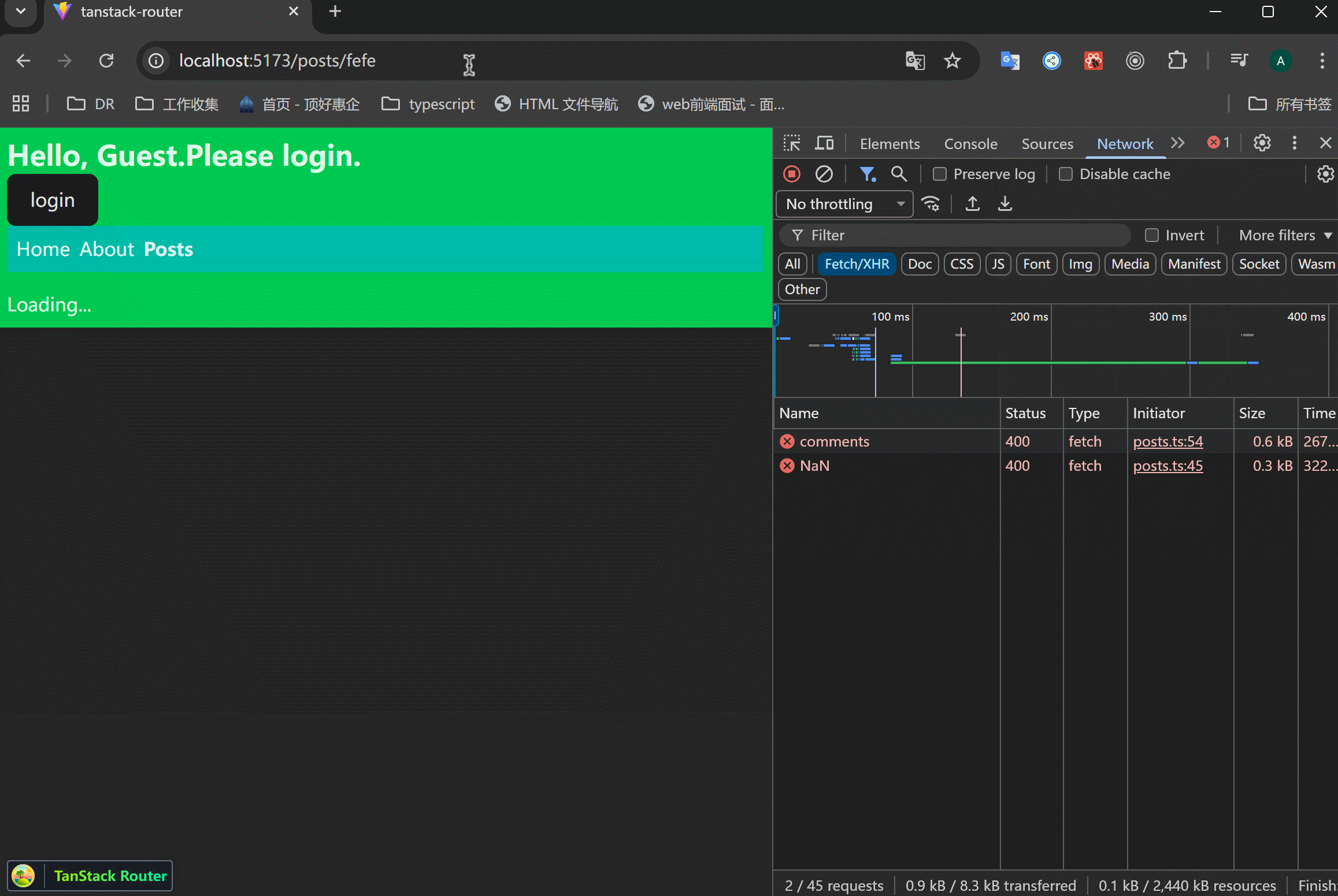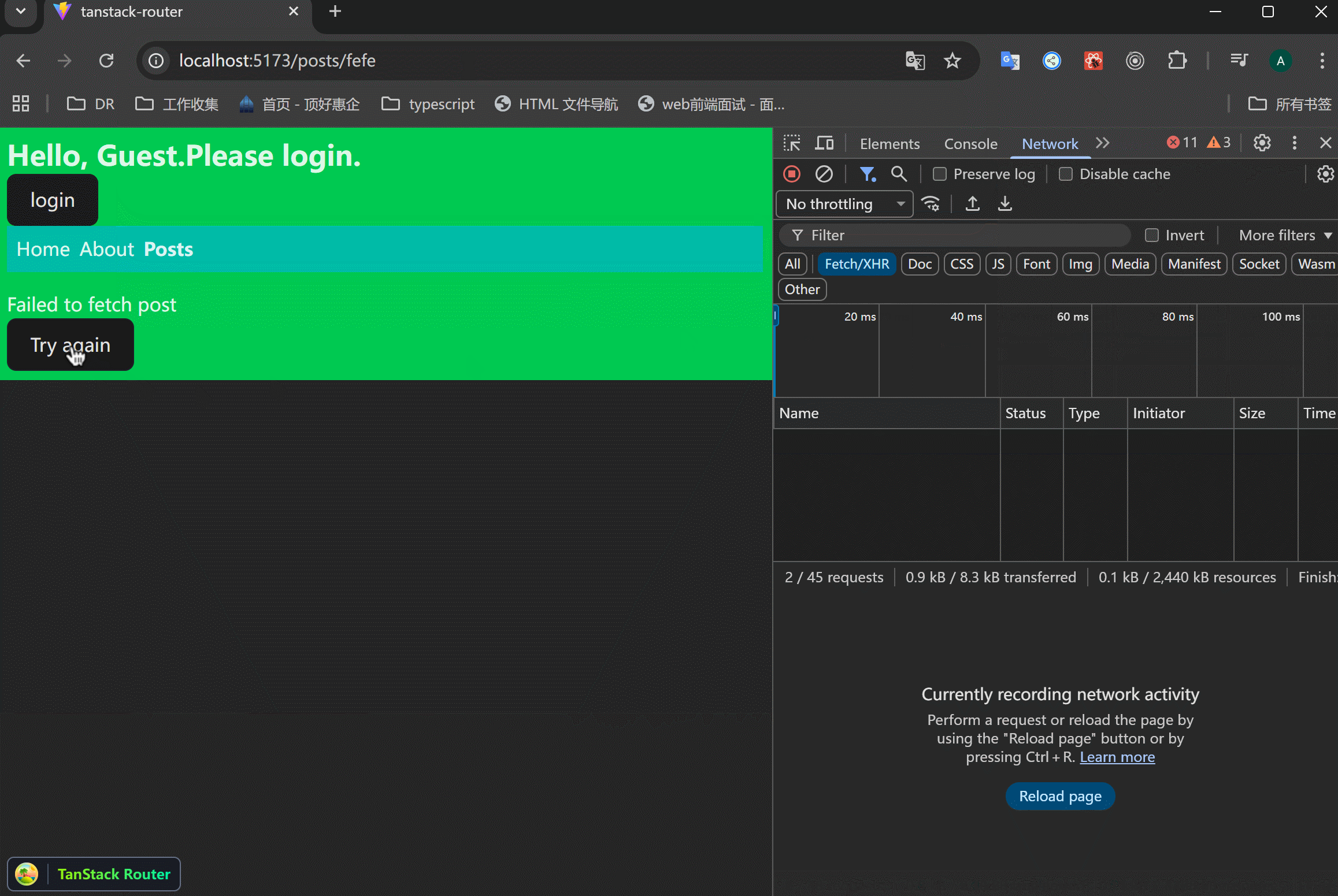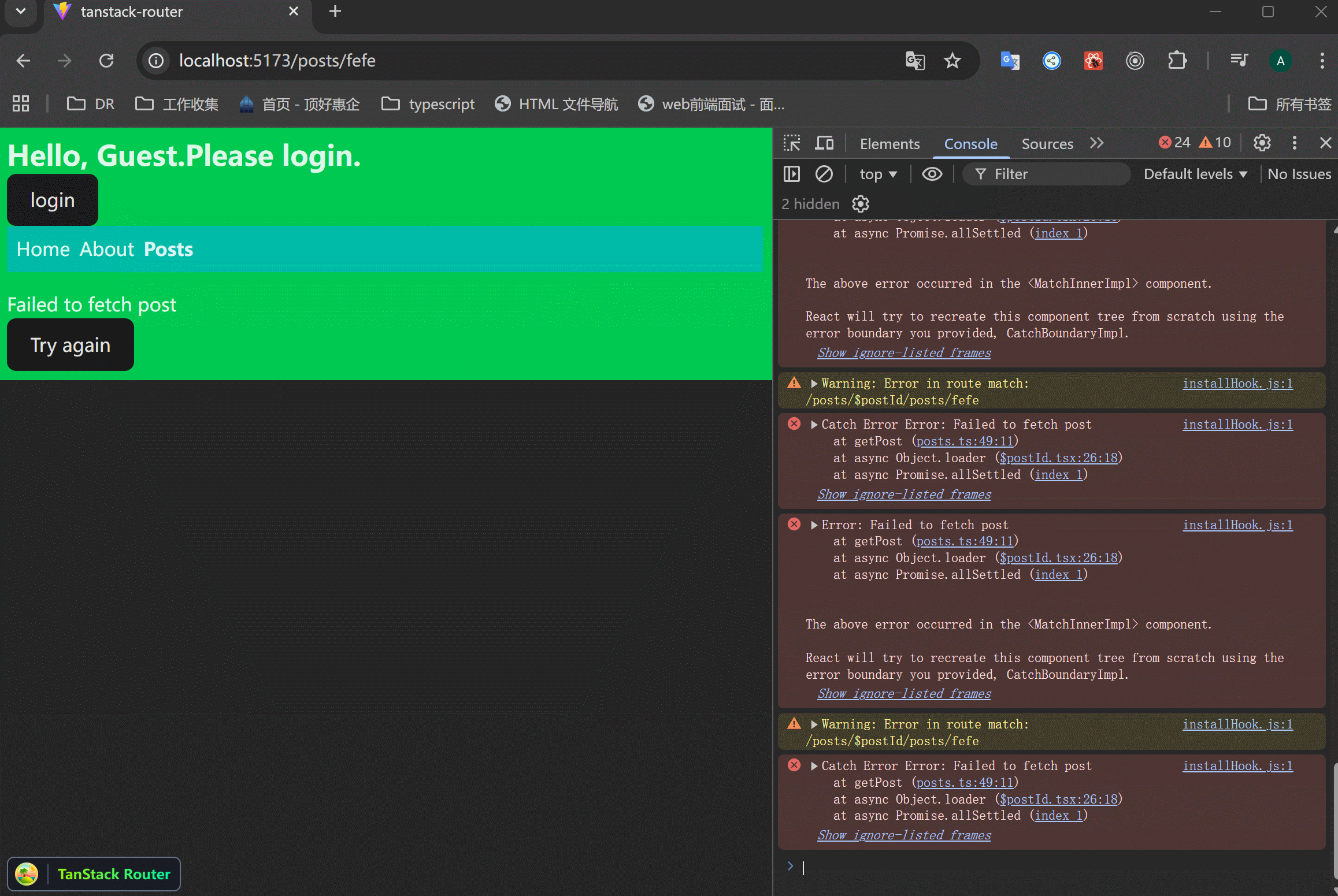
可以使用router.inValidate()来刷新路由。

可以看到,点击重试按钮之后,重新发起了请求。这对于因为网络造成的页面错误是有用的。
为什么 reset() 不 refetch loader?reset() 的作用是:
- 重置当前路由的错误边界(error boundary)状态
- 尝试重新渲染出错的组件(component)
- 只在组件渲染阶段(render)抛出的错误时有效,会重新走 render 流程
但你的 loader 是在路由加载阶段(load phase)执行的:
- loader → beforeLoad → validateSearch 等阶段抛出的错误
- 这些是路由解析/数据加载阶段的错误
当错误发生在 loader 里时:
- reset() 不会重新执行 loader,也不会重新跑整个路由加载流程
- 它只重试组件渲染 → 但因为 loader 没重新跑,数据还是缺失/错误 → 很可能又抛错 → 死循环或无效
社区常见 issue(如 #2539)已经确认了这一点:
If an error occurs in beforeLoad/loader/... then calling reset() will not try to run the route again.
Not Found Errors
在 TanStack Router 中,notFound(404 错误)的处理主要分为两个维度:全局配置和组件内手动触发。
与一般的 errorComponent 不同,notFound 专门用于处理“路径匹配成功但资源不存在”或“路径完全无法匹配”的情况。
1. 处理“路径无法匹配” (全局 404)
当用户访问了一个在路由树(Route Tree)中根本不存在的 URL 时,会触发全局的 NotFound 逻辑。
你需要在 createRouter 中配置 defaultNotFoundComponent:
xxxxxxxxxx121const router = createRouter({2 routeTree,3 // 当找不到任何匹配路由时显示4 defaultNotFoundComponent: () => {5 return (6 <div>7 <h1>404 - 页面走丢了</h1>8 <Link to="/">返回首页</Link>9 </div>10 )11 },12})2. 处理“资源不存在” (手动触发 404)
这是最常见的场景:用户访问 /posts/123,路由匹配成功了,但数据库里没有 ID 为 123 的文章。此时你应该在 loader 或组件中手动抛出 notFound()。
在 Loader 中触发:
xxxxxxxxxx171import { notFound } from '@tanstack/react-router'23export const Route = createFileRoute('/posts/$postId')({4 loader: async ({ params }) => {5 const post = await fetchPost(params.postId)6 7 if (!post) {8 // 抛出这个错误会立即停止后续执行,并跳转到 NotFound UI9 throw notFound() 10 }11 12 return post13 },14 15 // 你可以为这个特定路由定义专属的 NotFound UI16 notFoundComponent: () => <div>该文章已被删除或不存在</div>17})3. notFound 与 errorComponent 的区别
很多开发者会混淆这两者,它们的触发逻辑完全不同:
| 特性 | notFoundComponent | errorComponent |
|---|---|---|
| 触发原因 | 手动调用 notFound() 或路径完全不匹配 | 代码崩溃、API 报错(500/网络超时等) |
| 语义 | "资源没找到" (404) | "程序出错了" (5xx/Runtime Error) |
| 默认行为 | 寻找最近的 notFoundComponent | 寻找最近的 errorComponent |
4. 嵌套路由中的 NotFound
TanStack Router 支持 局部 404。
- 如果你在
posts.tsx(父路由)中定义了notFoundComponent。 - 当子路由
/posts/$postId抛出notFound()时。 - 效果:父路由的导航栏、侧边栏依然存在,只有中间的内容区域会被替换为
posts.tsx定义的notFoundComponent。
5. 常见配置项汇总
除了组件本身,你还可以在路由定义中配置:
onNotFound: 类似于onError,当触发 404 时执行的副作用(比如发送埋点统计哪些链接失效了)。notFoundMode: 决定如何渲染。默认是'fuzzy'(模糊匹配,寻找最近的定义)。
总结建议
- 必须设置:在
createRouter里给个defaultNotFoundComponent兜底。虽然tanstack为我们做了默认的notFound功能,但最好还是自己做一个样式合适的页面。 - 按需设置:在详情页(如用户、商品、文章)的路由里定义具体的
notFoundComponent,提供更精准的引导(比如“换个关键词搜搜”)。
CatchBoundary
在 TanStack Router 中,CatchBoundary 是一个专门用于局部捕获并处理渲染错误的底层组件。虽然你已经在路由配置中看到了 errorComponent,但 CatchBoundary 提供了更细粒度的控制,尤其是在处理非路由级别的组件崩溃时。
1. 核心定义
CatchBoundary 本质上是 React 错误边界(Error Boundary)的一个封装。它的作用是:当其子组件在渲染过程中抛出错误时,捕获该错误并展示一个“降级 UI”,而不是让整个路由或整个页面崩溃。
2. 与 errorComponent 的区别
这是最容易混淆的地方,两者的分工如下:
| 特性 | errorComponent (路由级) | CatchBoundary (组件级) |
|---|---|---|
| 触发点 | loader 失败或路由主组件崩溃 | 任何被它包裹的子组件崩溃 |
| 控制粒度 | 替换整个路由出口(Outlet) | 只替换被包裹的局部区域 |
| 使用场景 | 处理页面级数据加载错误 | 处理复杂的局部 UI 组件(如第三方图表)崩溃 |
3. 如何使用 CatchBoundary
你可以在任何组件树中使用它来包裹可能存在风险的代码块。
xxxxxxxxxx231import { CatchBoundary } from '@tanstack/react-router'23function MyComplexDashboard() {4 return (5 <div>6 <nav>侧边栏始终可见</nav>7 8 {/* 使用 CatchBoundary 包裹不稳定的组件 */}9 <CatchBoundary10 // 当报错时显示的 UI11 getResetKey={() => 'reset-key'} // 必填:用于重置边界的键。虽然暂时不知道有什么作用12 errorComponent={({ error, reset }) => (13 <div>14 <p>这个图表组件崩了:{error.message}</p>15 <button onClick={reset}>尝试修复并重置</button>16 </div>17 )}18 >19 <UnstableChartComponent />20 </CatchBoundary>21 </div>22 )23}4. 关键属性说明
errorComponent: 这是必填项,定义了报错时渲染的内容。它接收error(错误对象)和reset(重置函数)。onCatch: 类似于路由配置中的onCatch,这是一个回调函数,当错误被捕获时触发,适合用于发送错误日志。getResetKey: 这是一个非常有用的功能。如果你返回一个值(比如路由路径或 ID),当这个值改变时,CatchBoundary会自动重置,尝试重新渲染子组件。
5. 为什么在 TanStack Router 中它很重要?
在现代 React 应用中,数据加载和 UI 渲染是高度耦合的。CatchBoundary 让你可以实现“容错性布局”:
- Loader 错误:由路由的
errorComponent处理。 - 渲染错误:由
CatchBoundary处理。 - 404 错误:由
notFoundComponent处理。
总结
CatchBoundary 是你的局部防火墙。如果你的页面里有一个非常复杂、容易报错的子组件(比如复杂的表格或第三方库渲染),用 CatchBoundary 把它围起来,就能保证即使它挂了,用户依然能操作页面的其他部分。
老师案例
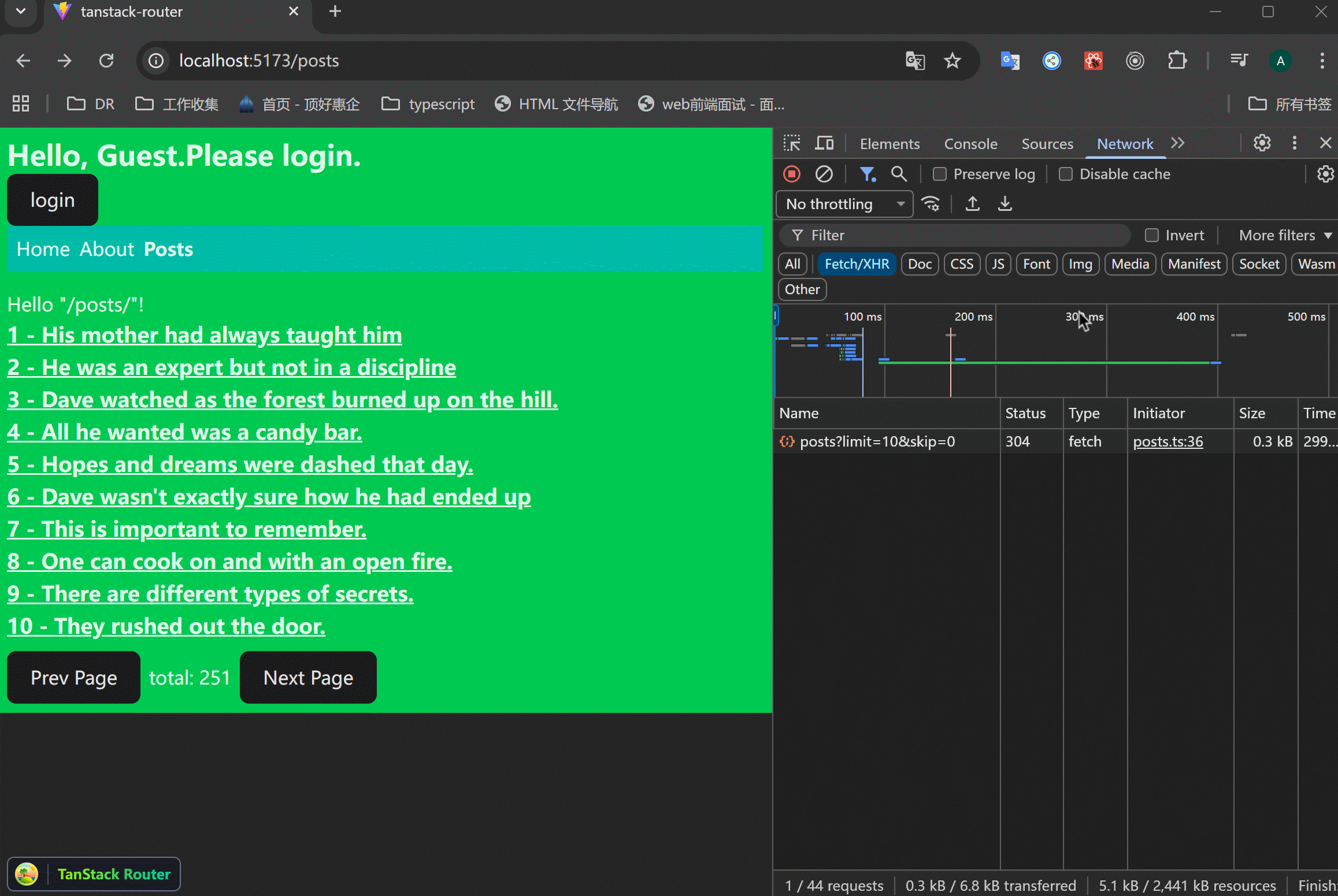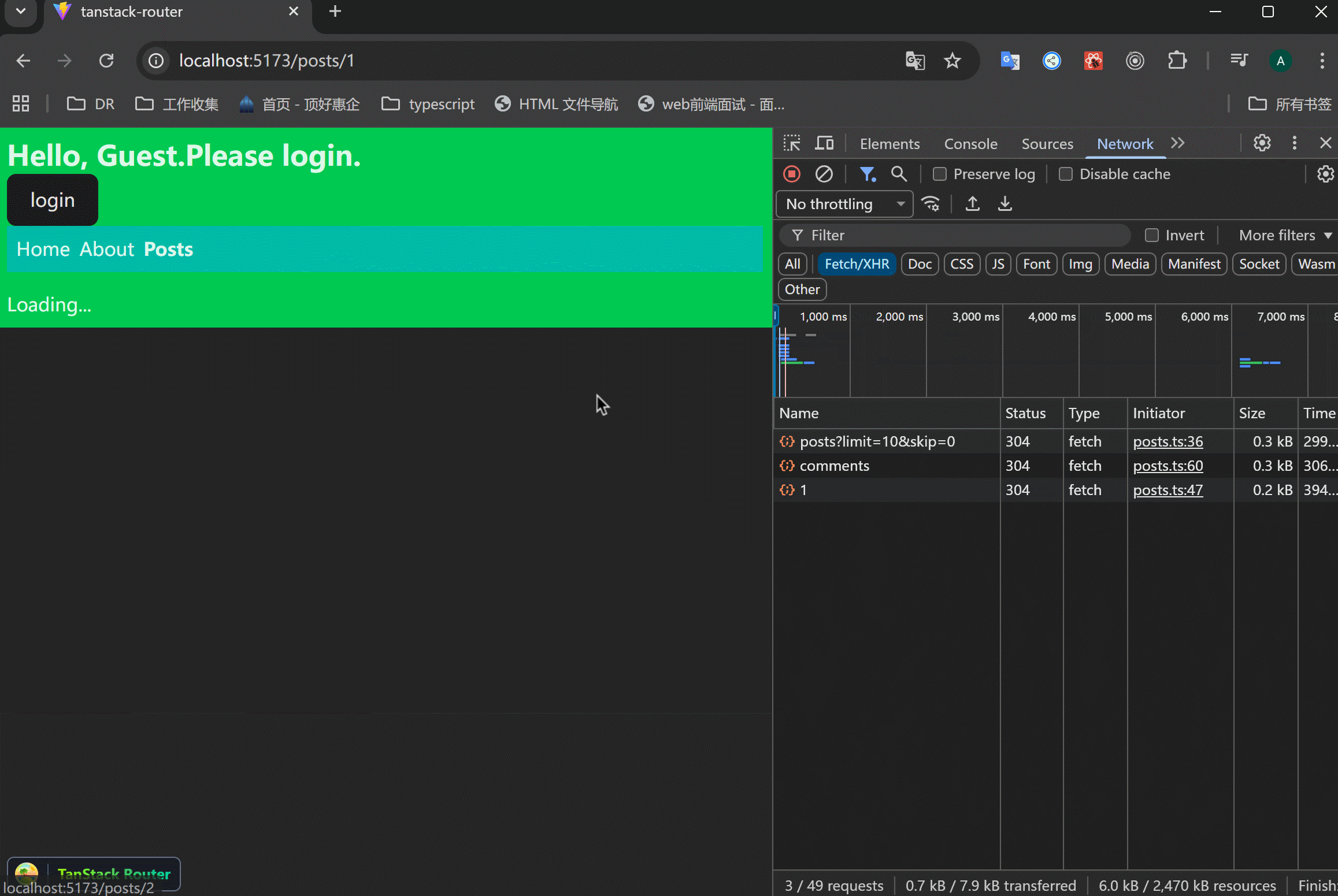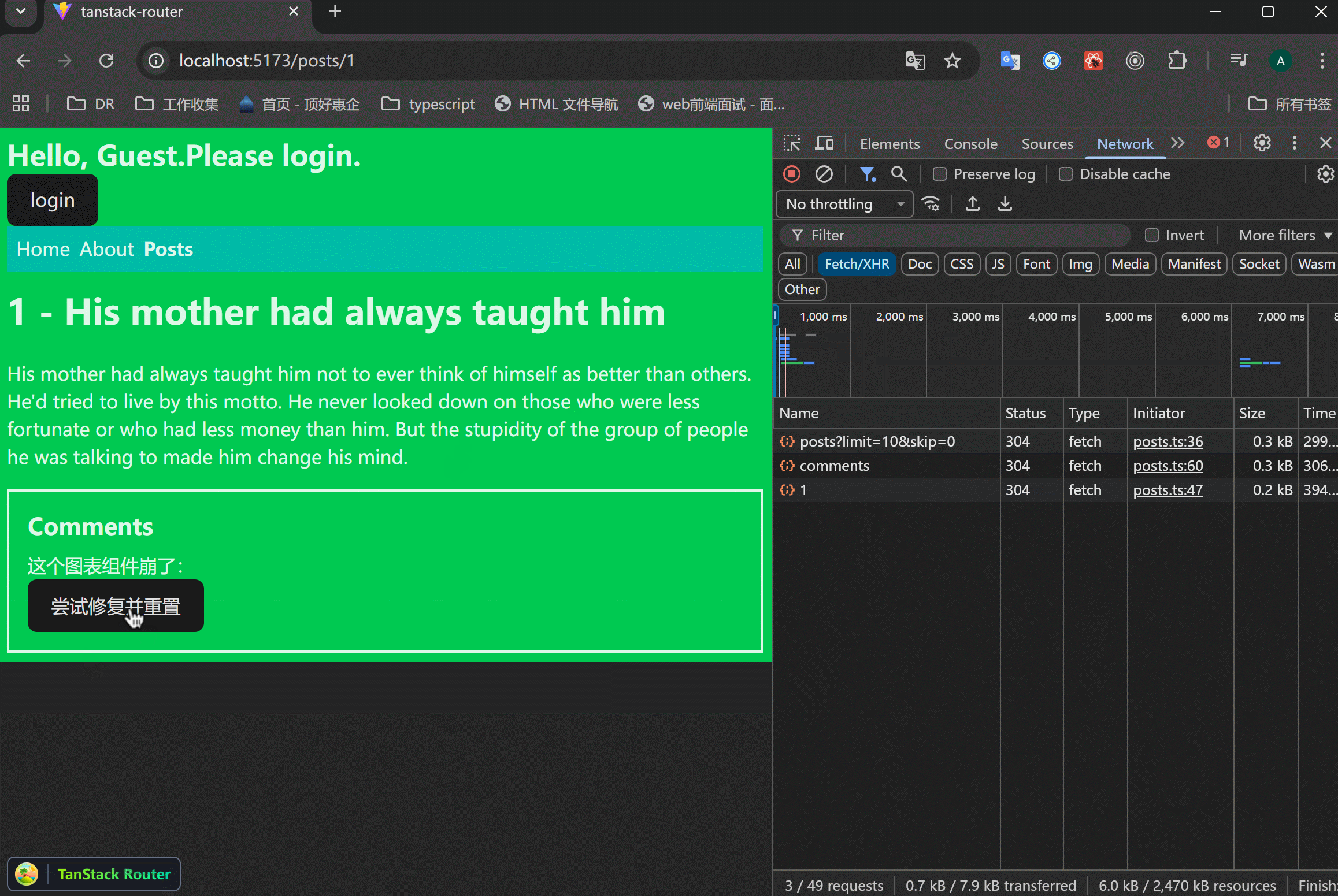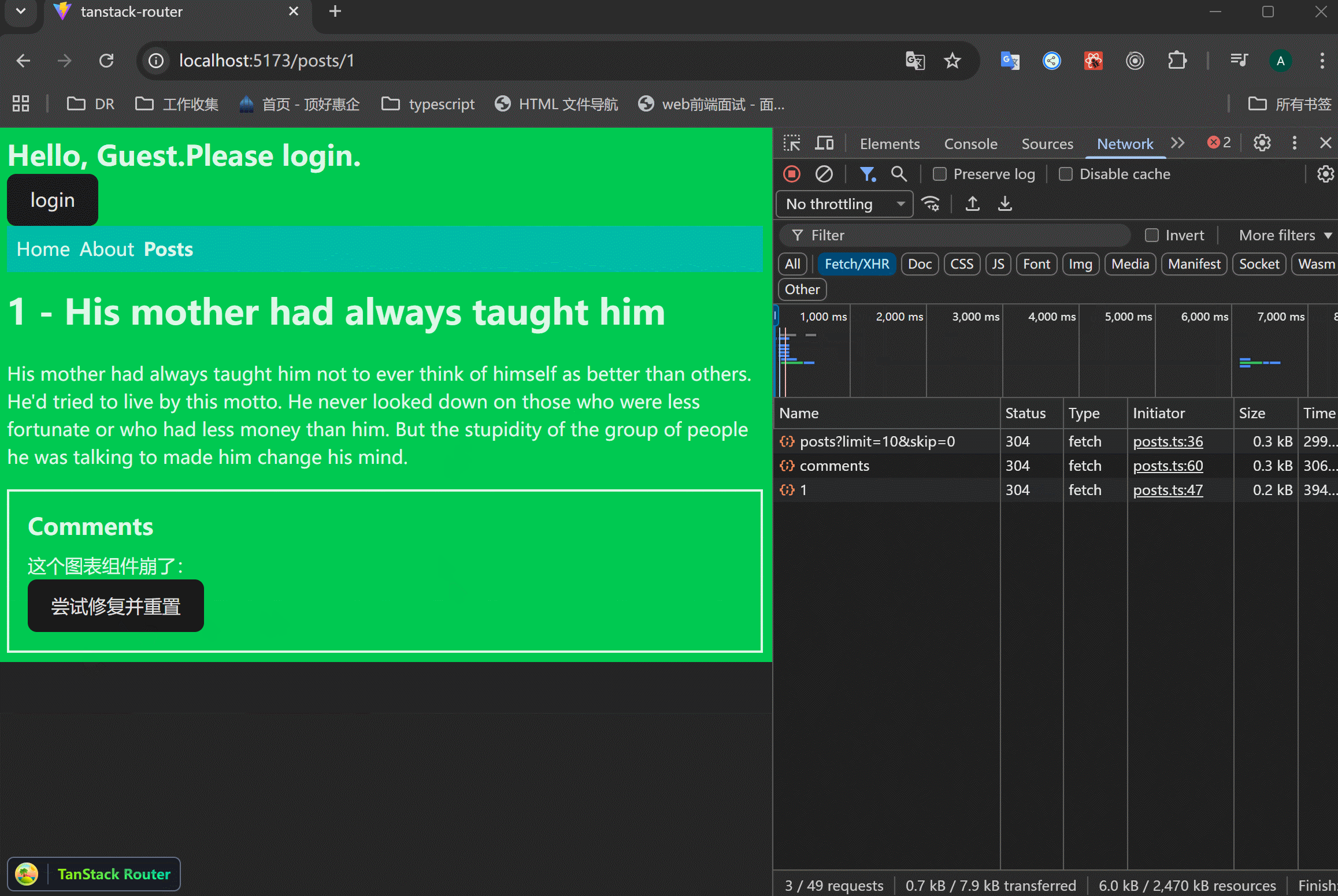
假设在请求comments的时候抛出了错误,此时整个页面都会显示errorComponent的内容:
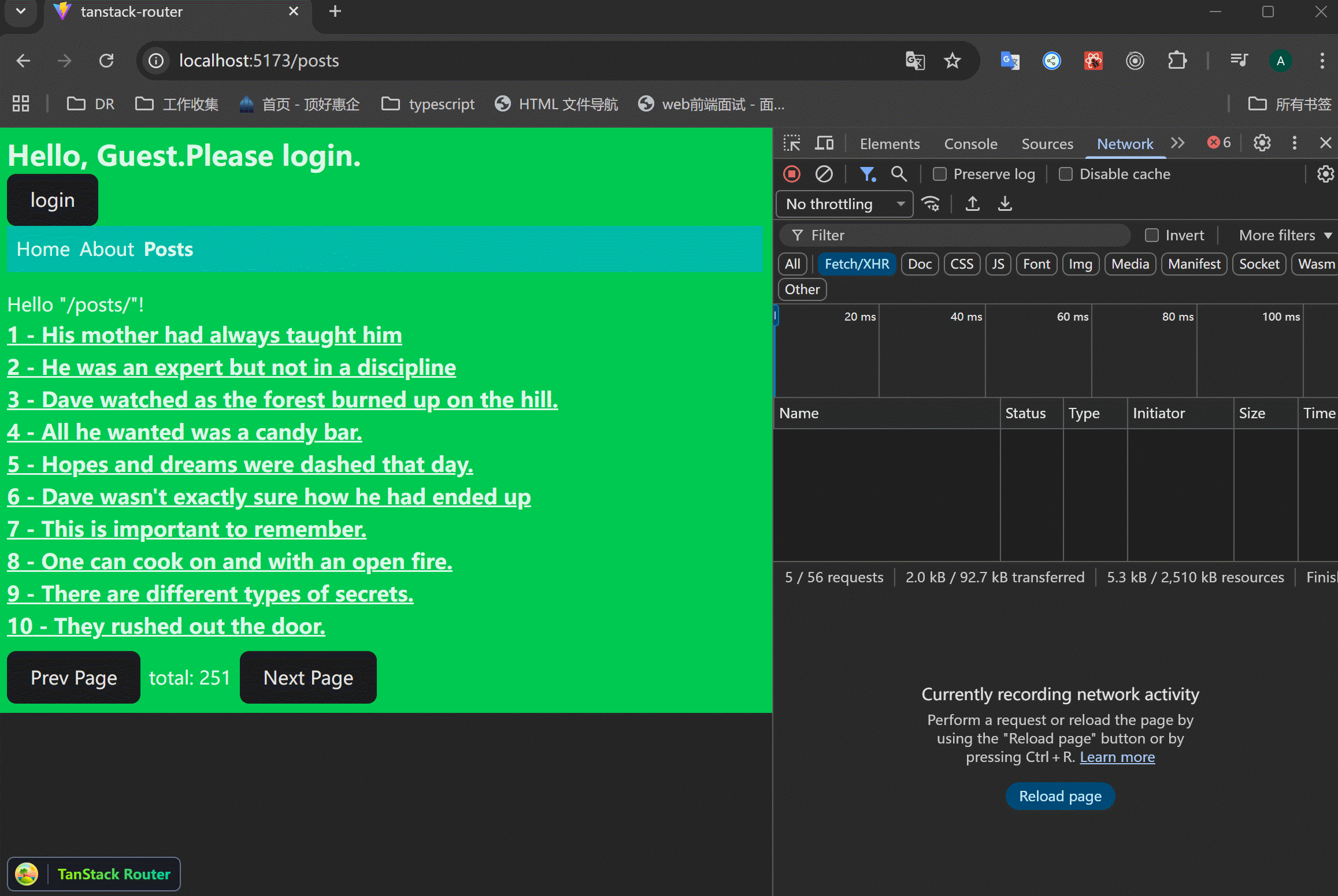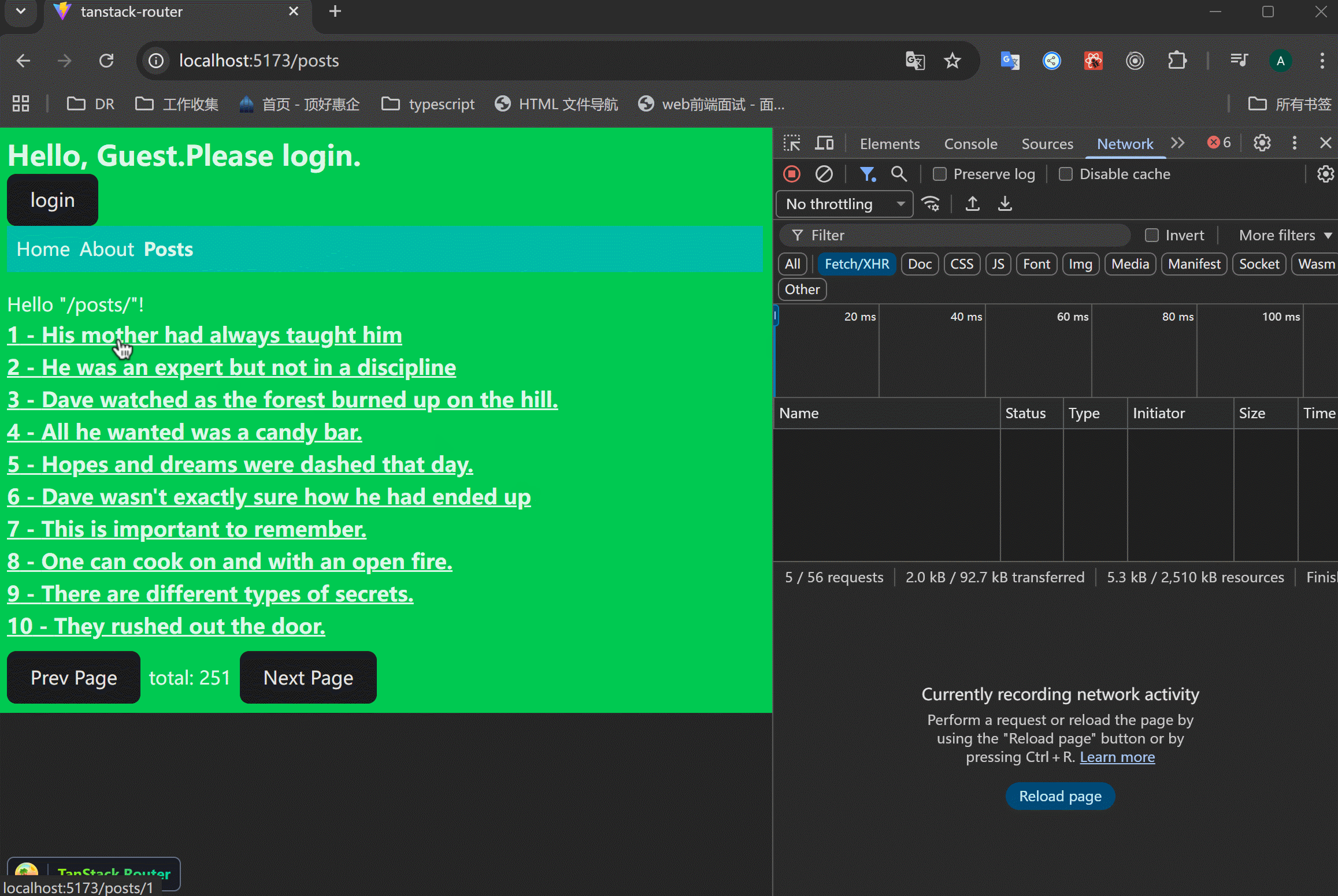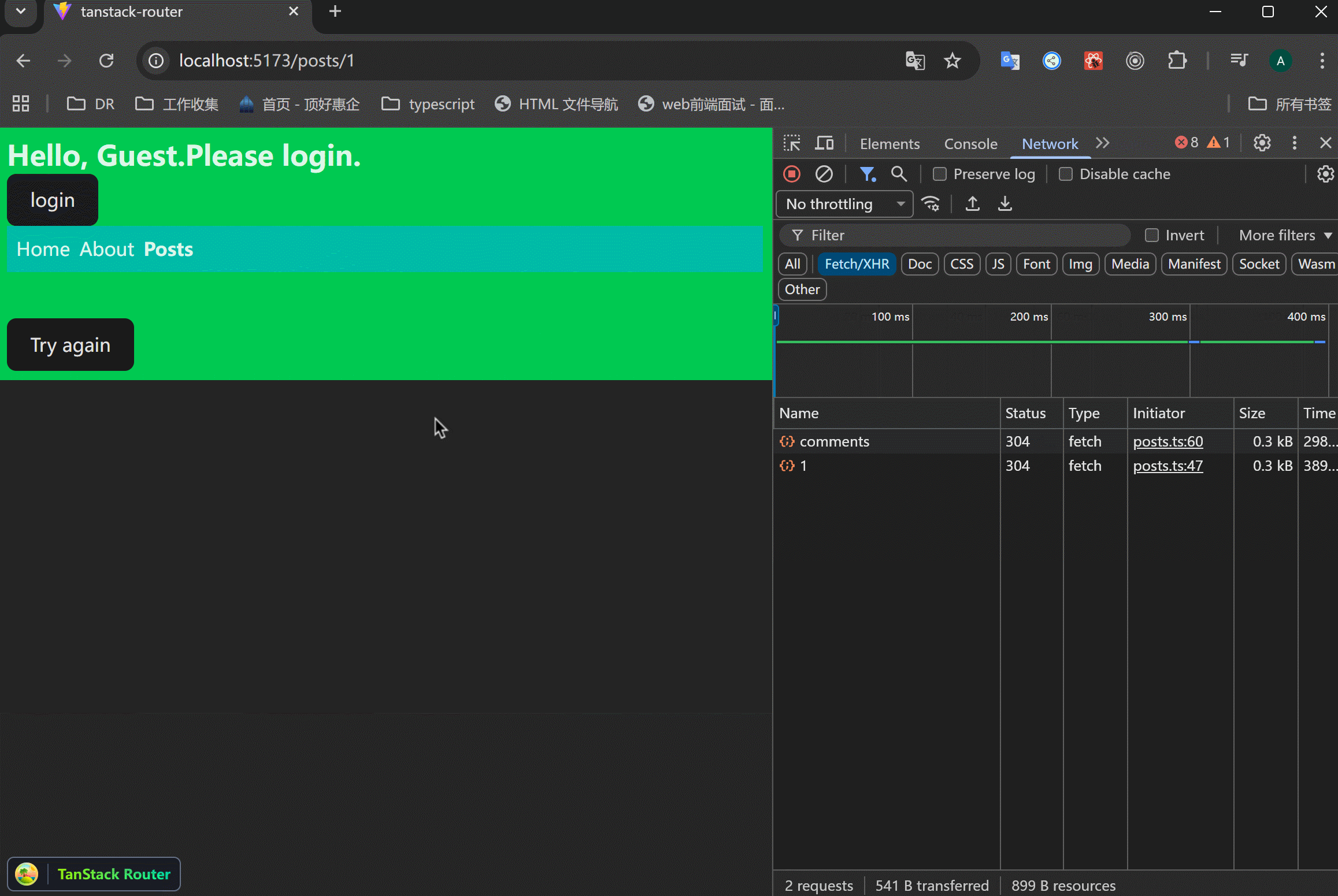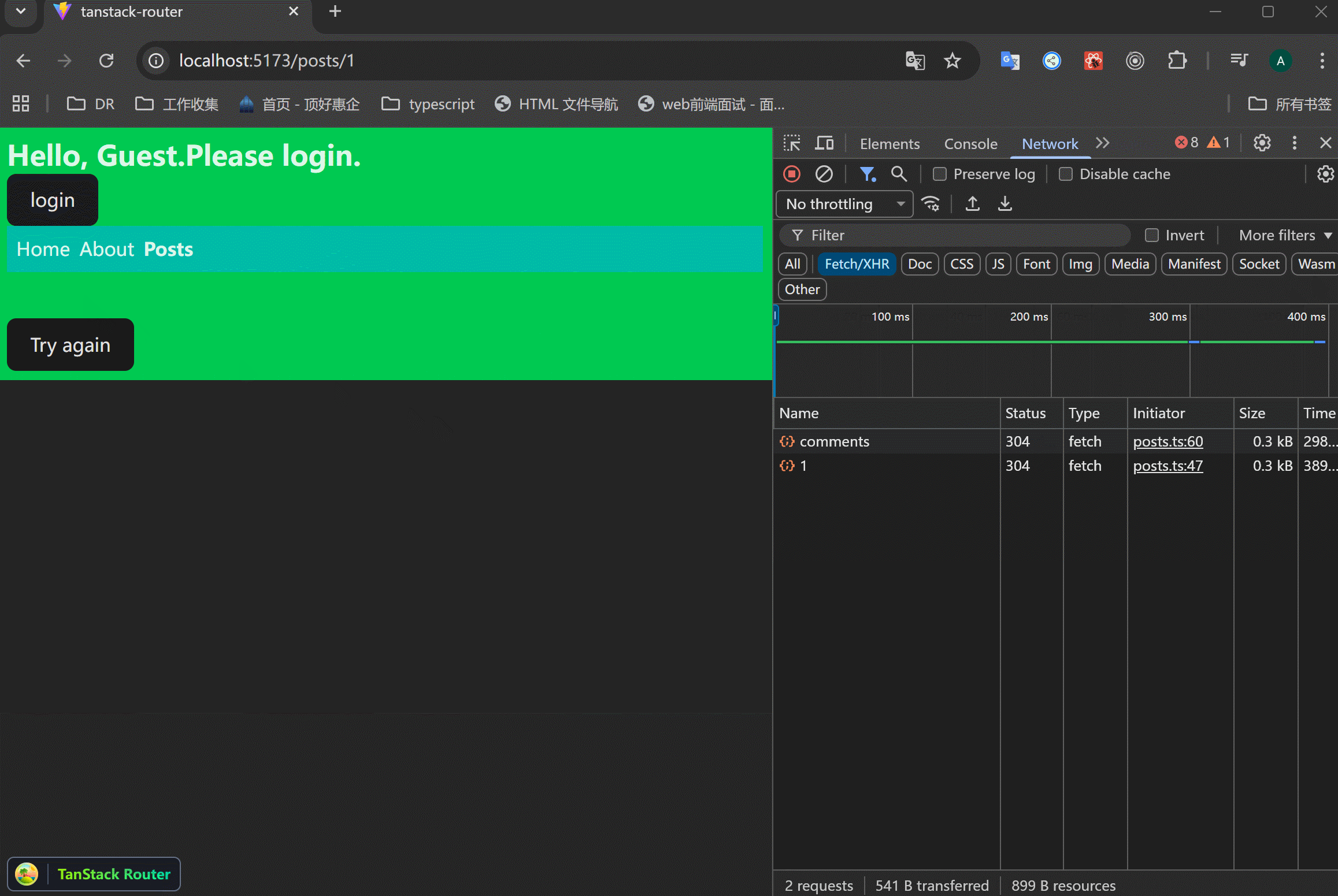
但是post部分是好的,我只想在comments部分出现错误时展示错误信息,此时就可以使用CatchBoundary来处理。
xxxxxxxxxx311// src/routes/posts/$postId.tsx23<Suspense fallback={<div>Comments Loading...</div>}>4 <CatchBoundary5 getResetKey={() => "ok"}6 errorComponent={({ error, reset }) => (7 <div>8 <p>这个组件崩了:{error.message}</p>9 <button onClick={reset}>尝试修复并重置</button>10 </div>11 )}>12 <Await promise={commentsPromise}>13 {(comments) => (14 <ul>15 {comments.comments.map((comment) => (16 <li17 key={comment.id}18 className="bg-purple-800 border p-2 mb-2">19 {comment.body}20 <br />21 <span className="text-sm text-gray-200">22 {" "}23 - {comment.user.username}24 </span>25 </li>26 ))}27 </ul>28 )}29 </Await>30 </CatchBoundary>31</Suspense>可以看到,只有comments部分显示报错内容,其余的部分都是好的,这很好啊。
Code Splitting
在 TanStack Router 中,Code Splitting(代码分割) 是提升首屏加载速度的核心技术。它的目标是:只加载当前页面所需的代码,而不是一次性下载整个应用的 JS 文件。
参考文档:https://tanstack.com/router/latest/docs/framework/react/guide/code-splitting
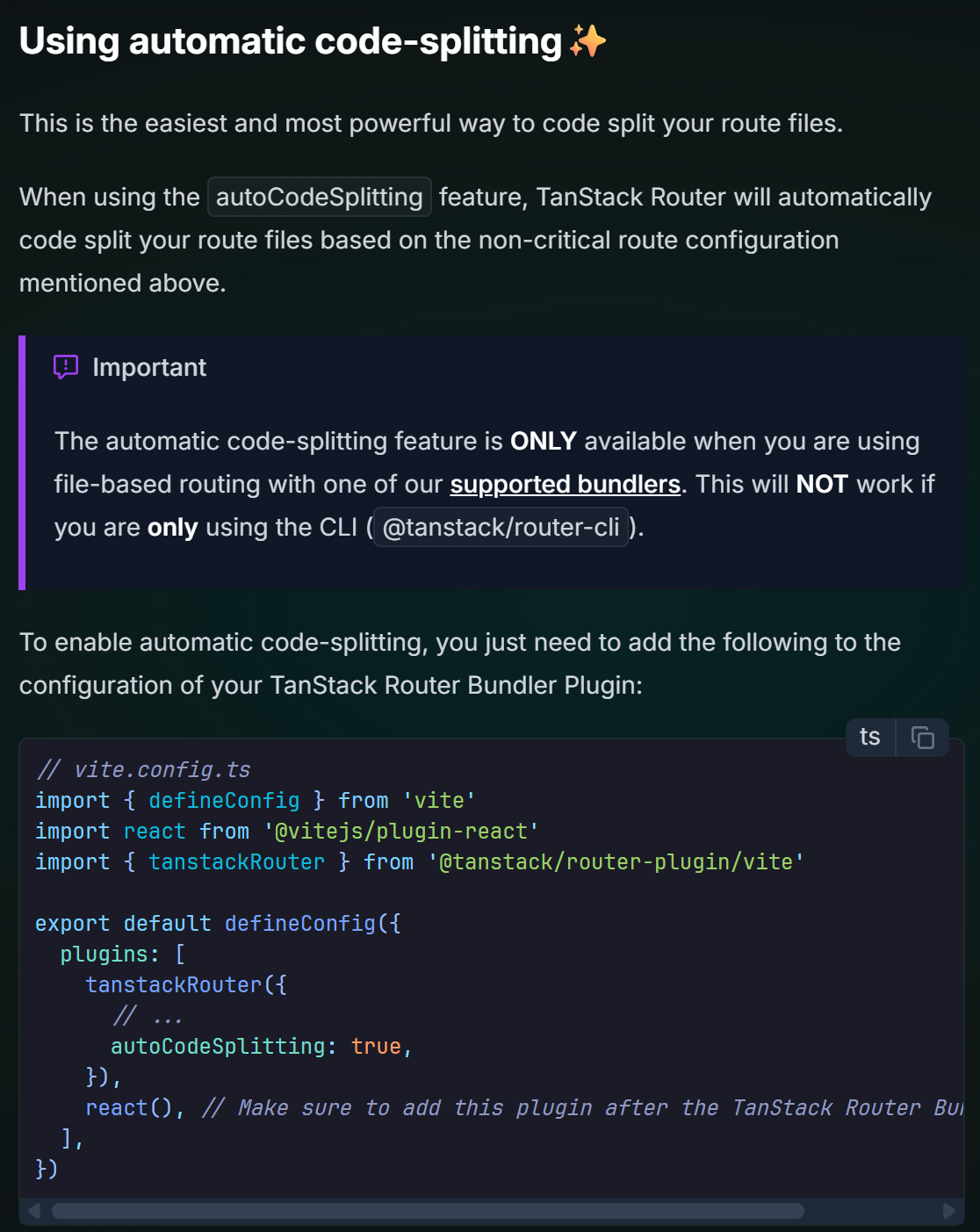
目前只需要关注下面这一点,自动分割即可,更加复杂的不要管了:
Preloading
在 TanStack Router 中,Preloading(预加载) 是一项旨在消除用户感知延迟的技术。它的核心思路是:在用户真正点击链接之前,就提前加载好该路由所需的代码(JS 束)和数据(Loader 数据)。
1. 预加载的触发时机 (Preload Strategies)
你可以通过 preload 属性控制什么时候开始预加载:
intent(最推荐):当用户的鼠标悬停(hover)在链接上,或者手指触摸到链接时,Router 会认为用户“打算”跳转,从而开始预加载。viewport:一旦链接进入浏览器的可视区域,就立即开始预加载。适合用于首页的瀑布流或重要入口。render:当<Link preload="render">被挂载(mount)到 DOM 时,TanStack Router 会立即(不等待任何用户交互)开始执行以下操作:- 运行目标路由的 loader(如果有)
- 加载代码分割的组件 chunk(如果使用了 lazy/code-splitting)
- 执行 validateSearch 等相关校验逻辑
这些资源会被提前缓存到路由器的内存中(preloaded matches),等待用户真正点击时可以几乎瞬间完成导航(理想情况下无 pending、无白屏)。
2. 预加载了什么内容?
当预加载触发时,Router 会并行执行以下两个任务:
- 代码预加载:下载该路由对应的
.lazy.tsx组件包。 - 数据预加载:执行该路由的
loader函数,并将结果存入缓存。
这样当用户最终点击时,由于代码和数据都已经准备就绪,页面可以实现瞬间切换,跳过全屏加载状态(Pending State)。
3. 如何配置 Preloading
全局配置
通常在 createRouter 中设置默认行为,这样全站的 <Link> 都会生效:
xxxxxxxxxx91const router = createRouter({2 routeTree,3 // 默认开启 intent 模式的预加载4 defaultPreload: 'intent',5 // 设置一个延迟毫秒数,只有当用户的鼠标在链接上停留时间超过这个值时,才会真正触发预加载逻辑。通常框架默认会有大约 50ms 的保底延迟。推荐范围:50ms - 150ms。6 defaultPreloadDelay: 100,7 // 预加载的数据在多少毫秒内被认为是“新鲜”的(默认 30s)8 defaultPreloadStaleTime: 30000, 9})局部配置
你也可以在具体的 <Link> 组件上覆盖全局设置:
xxxxxxxxxx61<Link 2 to="/posts" 3 preload="intent" // 或者设置为 false 禁用4>5 查看文章6</Link>社区目前的主流做法是:
- 全局 defaultPreload: 'intent'(性价比最高)
- 少数核心链接 单独设置 preload="render"
4. 预加载的“保鲜期”:preloadStaleTime
为了防止浪费流量(例如用户频繁 hover 多个链接),Router 使用了 preloadStaleTime:
- 如果一个路由在
30s(默认值)内被预加载过,且数据未过期,那么第二次 hover 时不会再次发起请求。 - 如果你希望每次 hover 都尝试获取最新数据,可以将这个值设为
0。
5. 手动触发预加载
有时候你需要通过代码手动触发预加载(例如在某个动画完成后),可以使用 router.preloadRoute:
xxxxxxxxxx51const router = useRouter()23const handleMouseEnter = () => {4 router.preloadRoute({ to: '/dashboard' })5}总结与对比
| 特性 | 无 Preloading | 有 Preloading (intent) |
|---|---|---|
| 点击瞬间 | 开始下载 JS + 请求数据 | 立即渲染组件 |
| 用户体验 | 看到 Loading 界面 | 秒开,无缝衔接 |
| 服务器压力 | 较低 | 略高(会有部分无效 hover 请求) |
预加载是让单页应用(SPA)产生“原生应用感”的关键。
老师案例
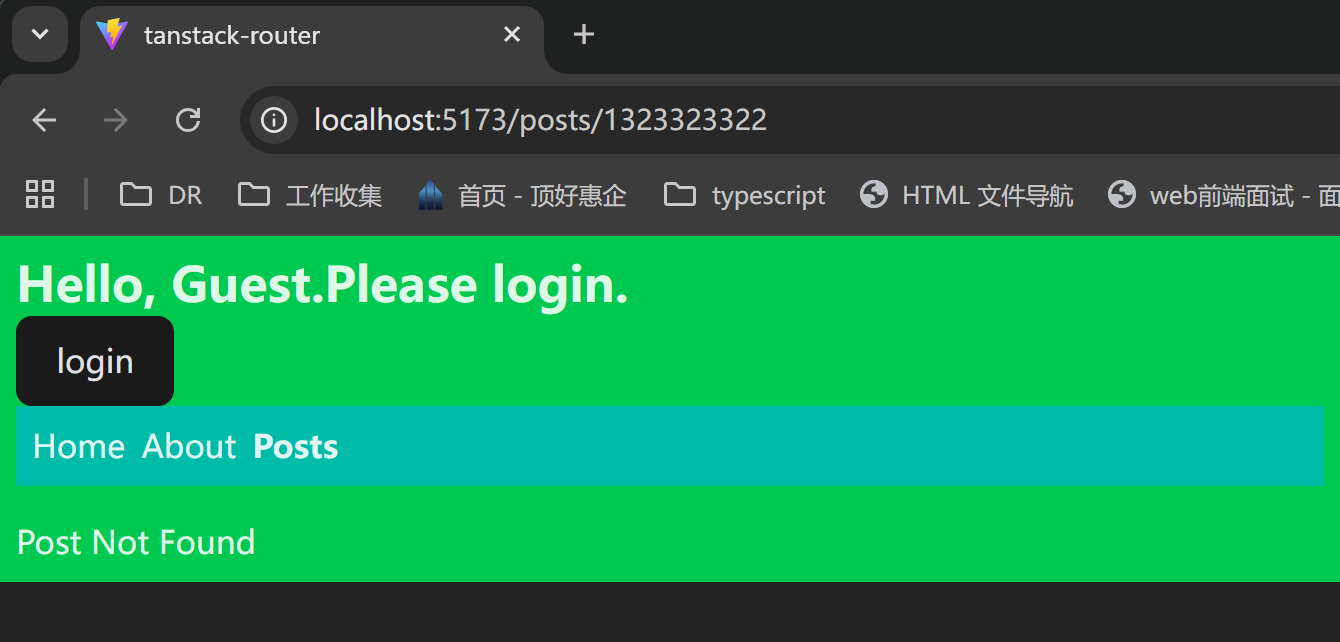
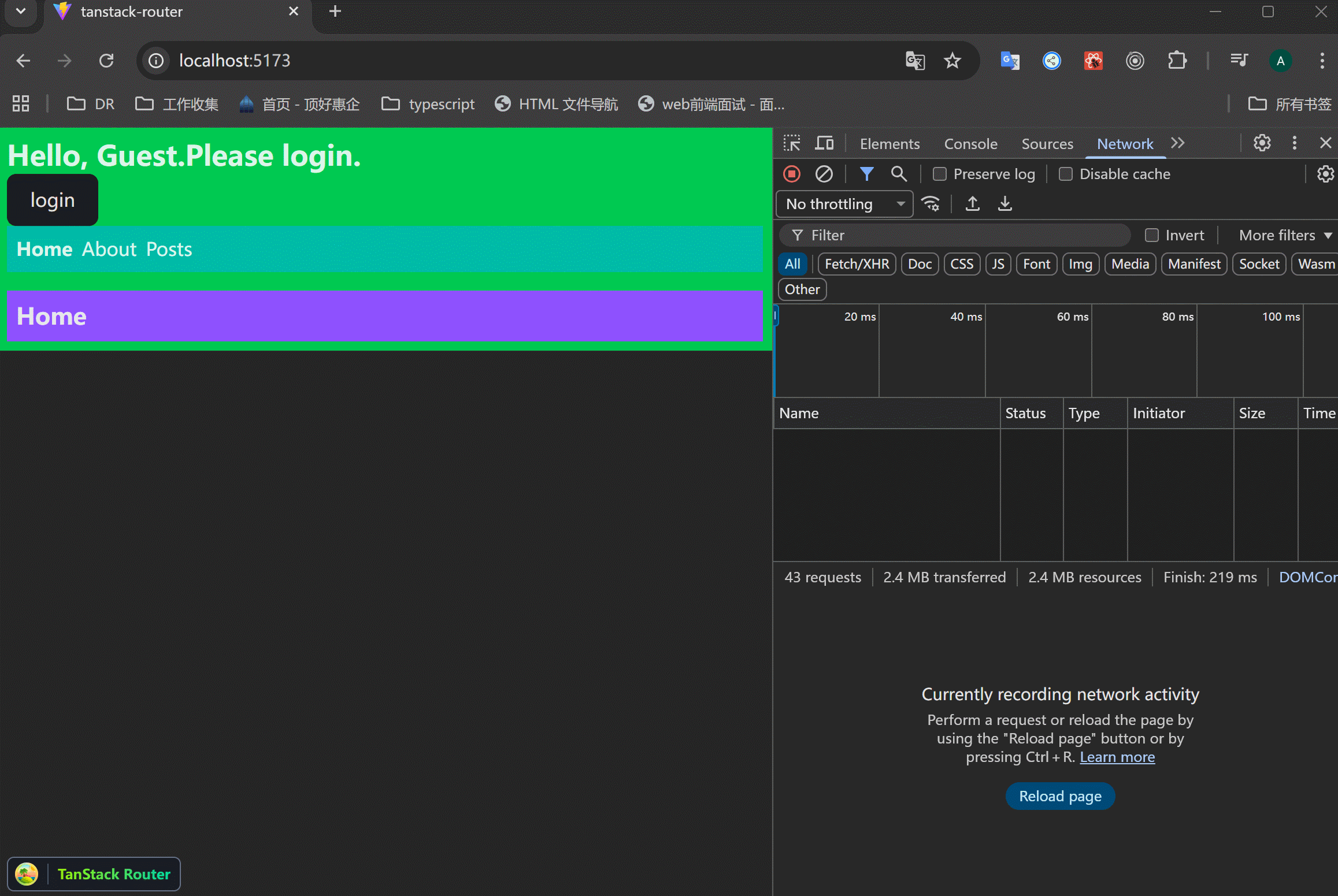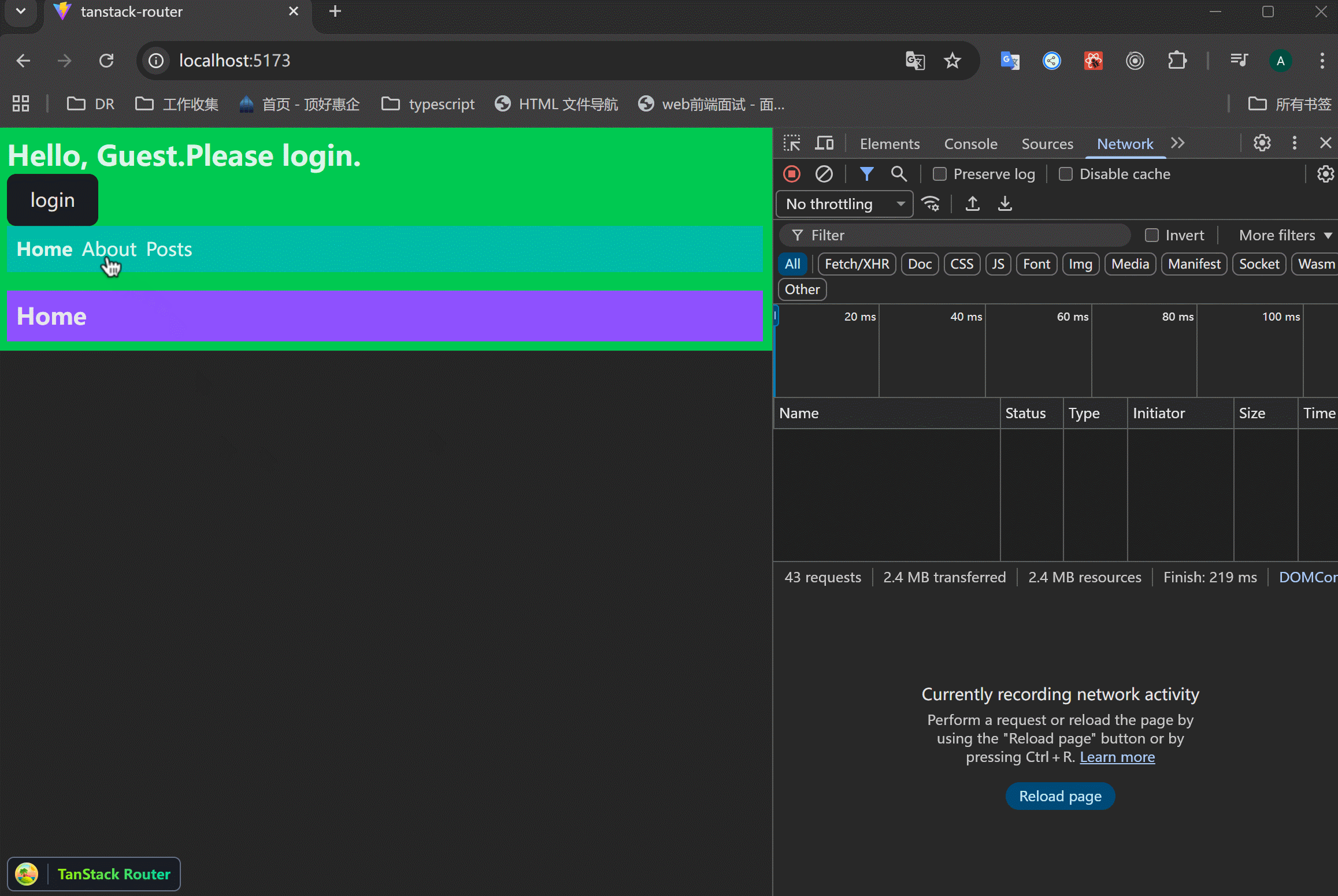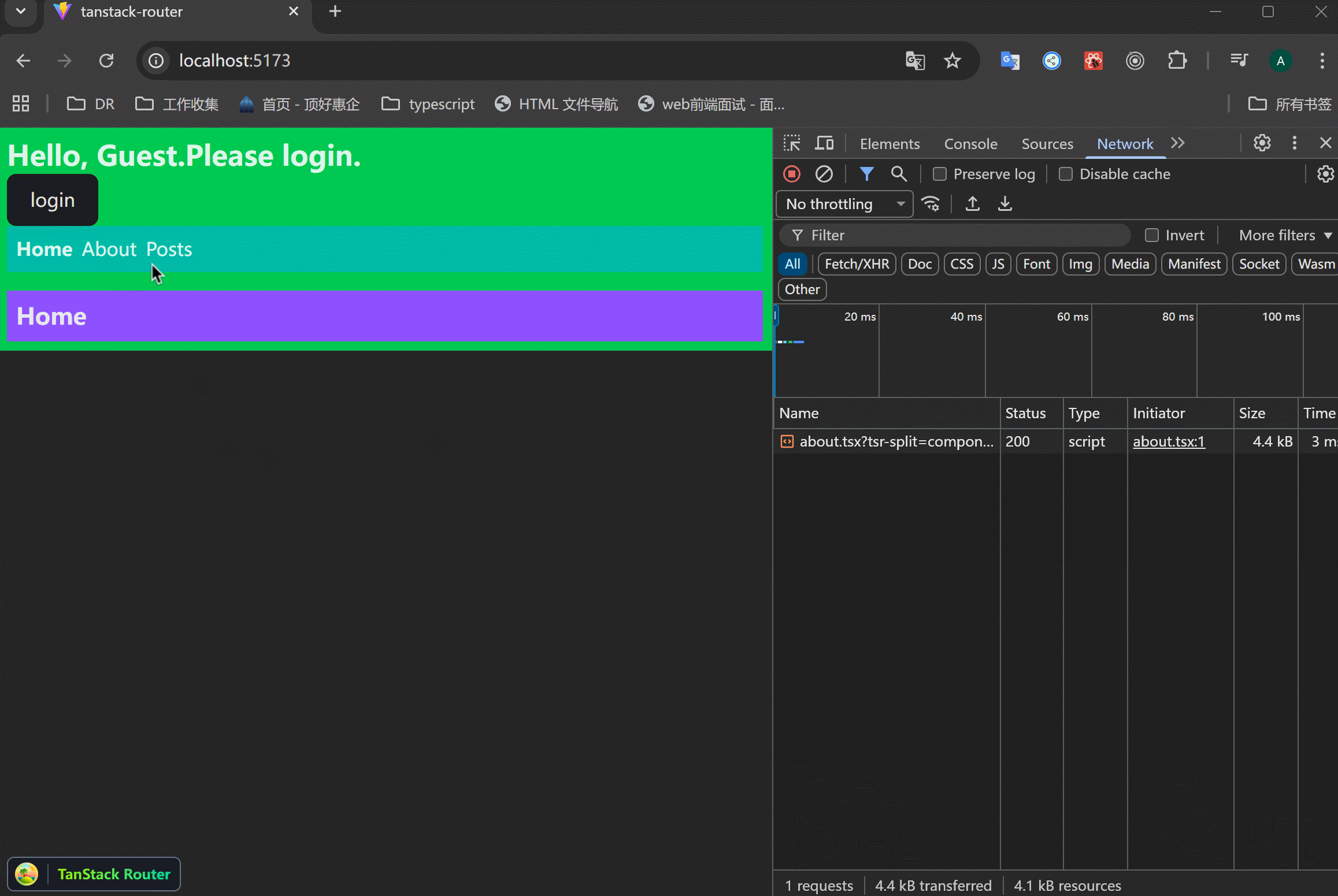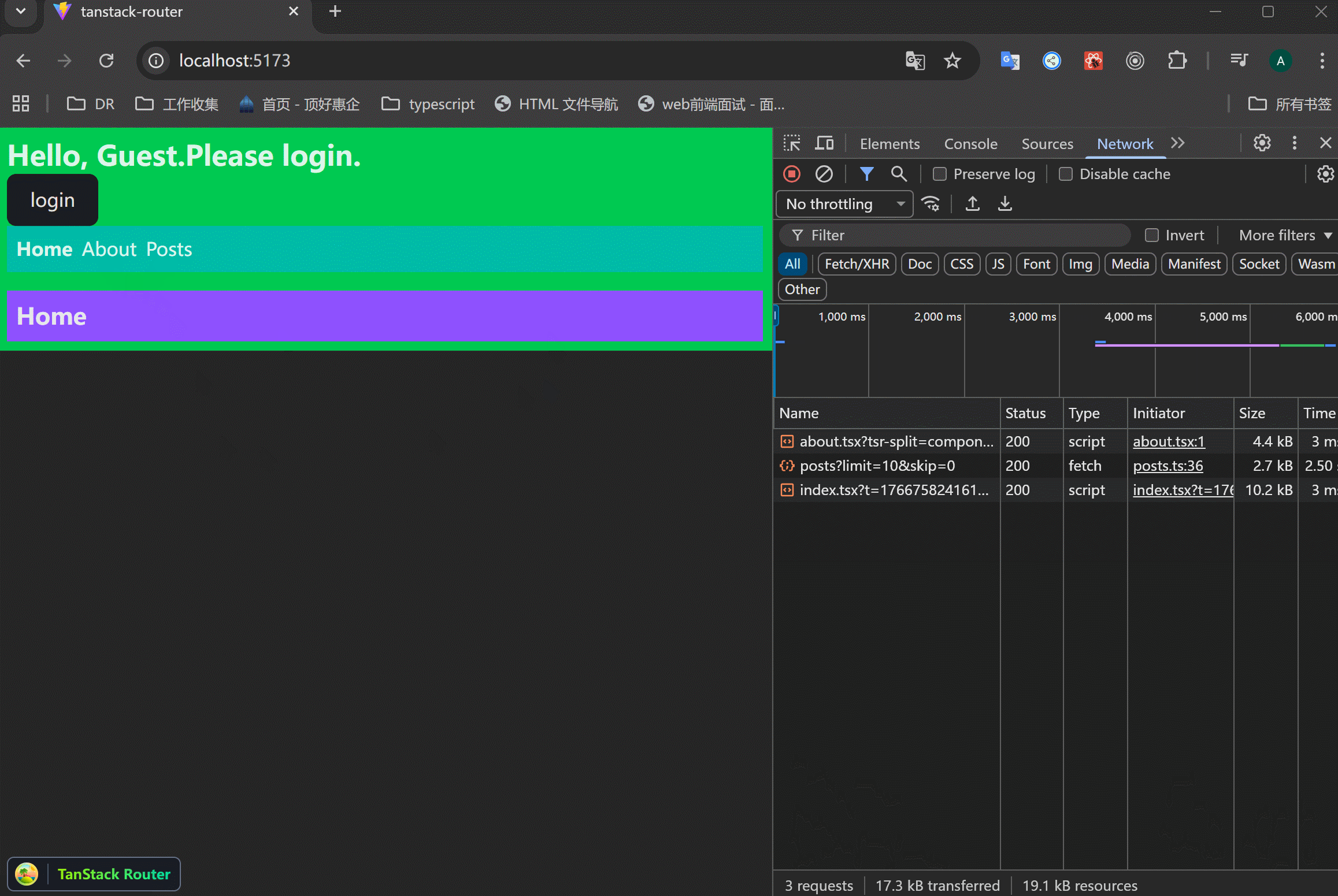
xxxxxxxxxx61<Link to="/about" preload="intent" className="[&.active]:font-bold">2 About3</Link>4<Link to="/posts" preload="intent" className="[&.active]:font-bold">5 Posts6</Link>可以看到,鼠标悬浮之后,里面的内容就会预加载。
Caching & Caching options
在 TanStack Router 中,缓存(Caching) 机制是其高性能的核心。它通过智能地管理数据的“新鲜度”和“生命周期”,确保应用在切换路由时能够瞬间响应,同时避免不必要的网络请求。
TanStack Router 的缓存逻辑深受 TanStack Query 的启发,主要围绕 staleTime 和 gcTime 这两个核心概念展开。
1. 核心概念:数据的三种状态
- Fresh(新鲜):数据刚获取不久,仍在
staleTime范围内。此时切换回该路由,Router 会直接使用缓存,完全不发起请求。 - Stale(陈旧):数据已超过
staleTime。此时切换回该路由,Router 会先显示旧缓存,同时在后台发起请求进行“静默刷新”(Background Refetch)。 - Inactive(不活跃):没有任何路由正在使用该数据(比如用户离开了相关路由)。
2. 两个关键参数
在 createRouter 的 defaultOptions 中,你可以全局控制缓存的行为:
| 参数 | 默认值 | 作用说明 |
|---|---|---|
staleTime | 0 ms | “保鲜期”。在此时间内,Router 认为数据是绝对可靠的,不会重新触发 loader。 |
gcTime | 30 分钟 | “垃圾回收期”。当数据进入“不活跃”状态后,在内存中保留的时间。超过后会被销毁。 |
配置示例:
xxxxxxxxxx91const router = createRouter({2 routeTree,3 defaultOptions: {4 // 数据 1 分钟内是新鲜的5 staleTime: 60000, 6 // 页面离开 10 分钟后清除内存中的缓存7 gcTime: 600000,8 },9})在 TanStack Router 中,
staleTime的默认值根据具体用途(路由数据缓存 vs. 预加载缓存)有所不同:
- 路由数据缓存 (Route Data Caching):默认值是 0 毫秒。这意味着默认情况下,每次匹配到路由时,数据都会被视为“陈旧”的,从而重新触发
loader。- 预加载缓存 (Preloading Caching):默认值是 30,000 毫秒(30 秒)。这是为了防止用户在短时间内多次悬停同一个链接而重复触发不必要的后台请求。
为什么路由缓存的默认值是 0?
TanStack Router 默认采用“积极验证”策略:
- 确保准确性:默认不缓存(0ms)可以保证用户每次进入页面看到的数据都是最新的。
- 触发机制:虽然
staleTime为 0,但如果数据已经在内存中且请求正在进行,Router 会智能处理,不会导致重复的并发请求。- 其实也更方便了,如果结合tanstack/query一起使用,就不用特别设置了。
3. 缓存如何与 Loader 协作?
当你点击一个链接时,TanStack Router 的缓存检查流程如下:
匹配路由:找到目标路由及其对应的
loader。检查缓存:
- 如果缓存中已有数据且处于 Fresh 状态:跳过 loader,直接渲染页面。
- 如果数据处于 Stale 状态:执行 loader,但在数据回来前,如果有旧数据会尝试展示。
- 如果没有缓存:执行
loader并显示pendingComponent(如果超时)。
4. 缓存失效与主动刷新
有时候你需要手动让缓存失效(例如提交表单后),可以通过以下方式:
router.invalidate():使当前所有活跃路由的缓存失效并重新触发加载。- 路由参数变化:默认情况下,如果
params或search参数发生变化,Router 会自动认为数据已失效并重新执行loader。
5. 缓存与预加载(Preloading)的联动
缓存机制让 Preloading 变得非常有意义:
- 当用户 hover 链接时,触发预加载。
- 数据被存入缓存并标记为 Fresh。
- 当用户正式点击时,Router 发现数据是 Fresh 的,实现瞬间秒开。
总结建议
- 对于静态或变动极少的数据(如用户信息、配置):设置较长的
staleTime(如 5 分钟)。 - 对于实时性强的数据(如股票、聊天记录):将
staleTime设为0。 - 注意:如果你同时使用了 TanStack Query,通常建议将路由层的缓存逻辑交给 Query 处理,让 Router 的
loader仅作为触发器。
老师案例
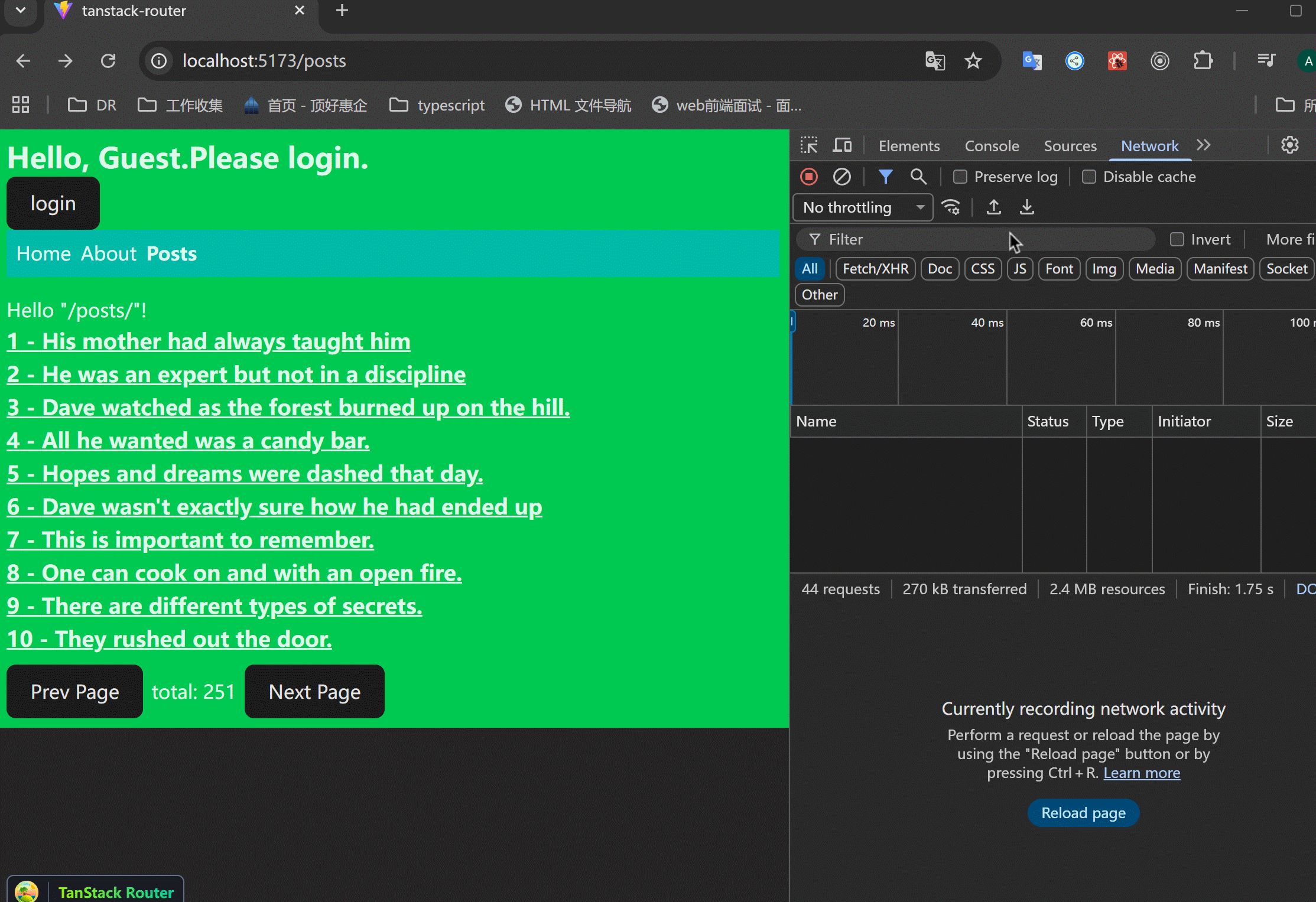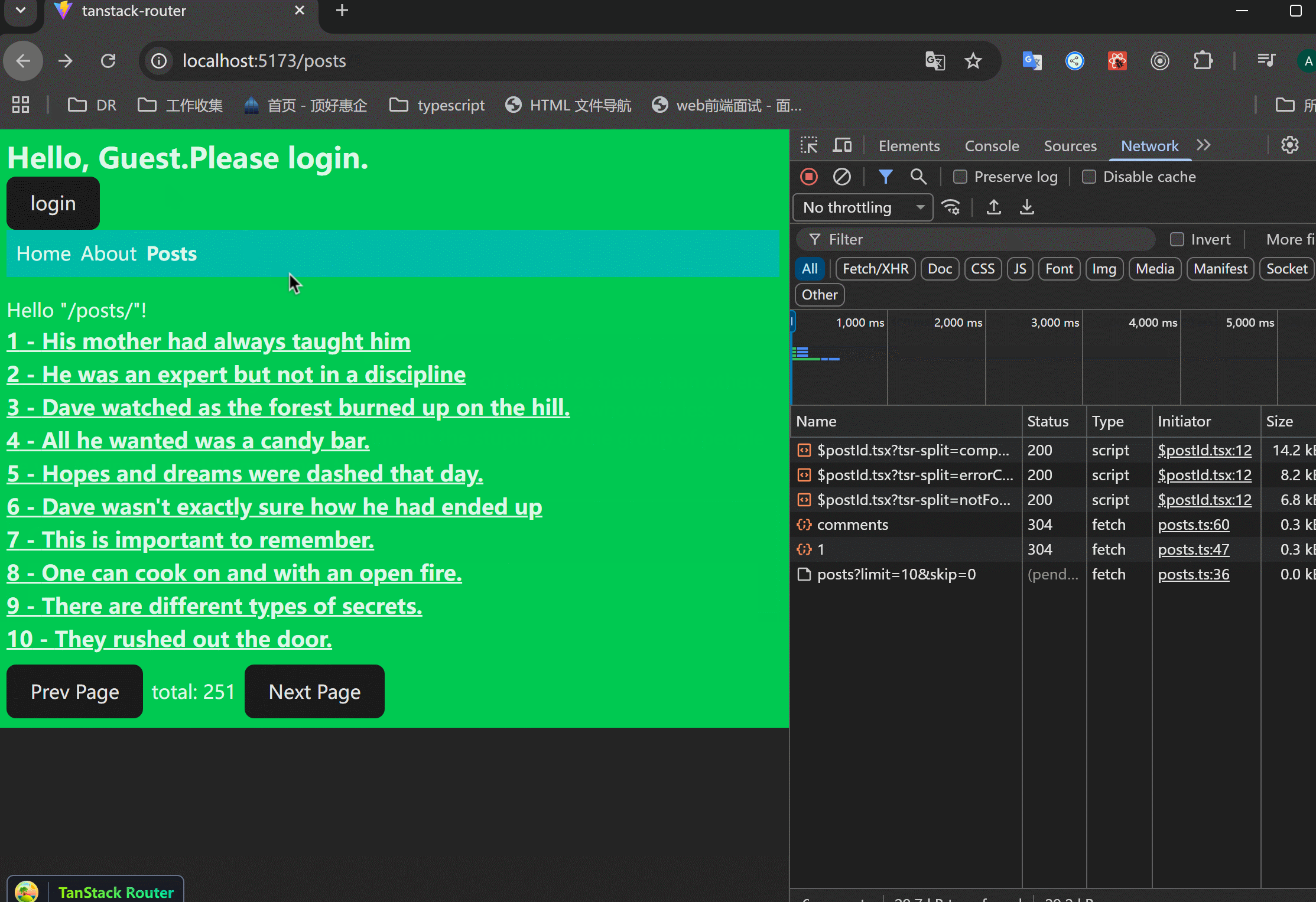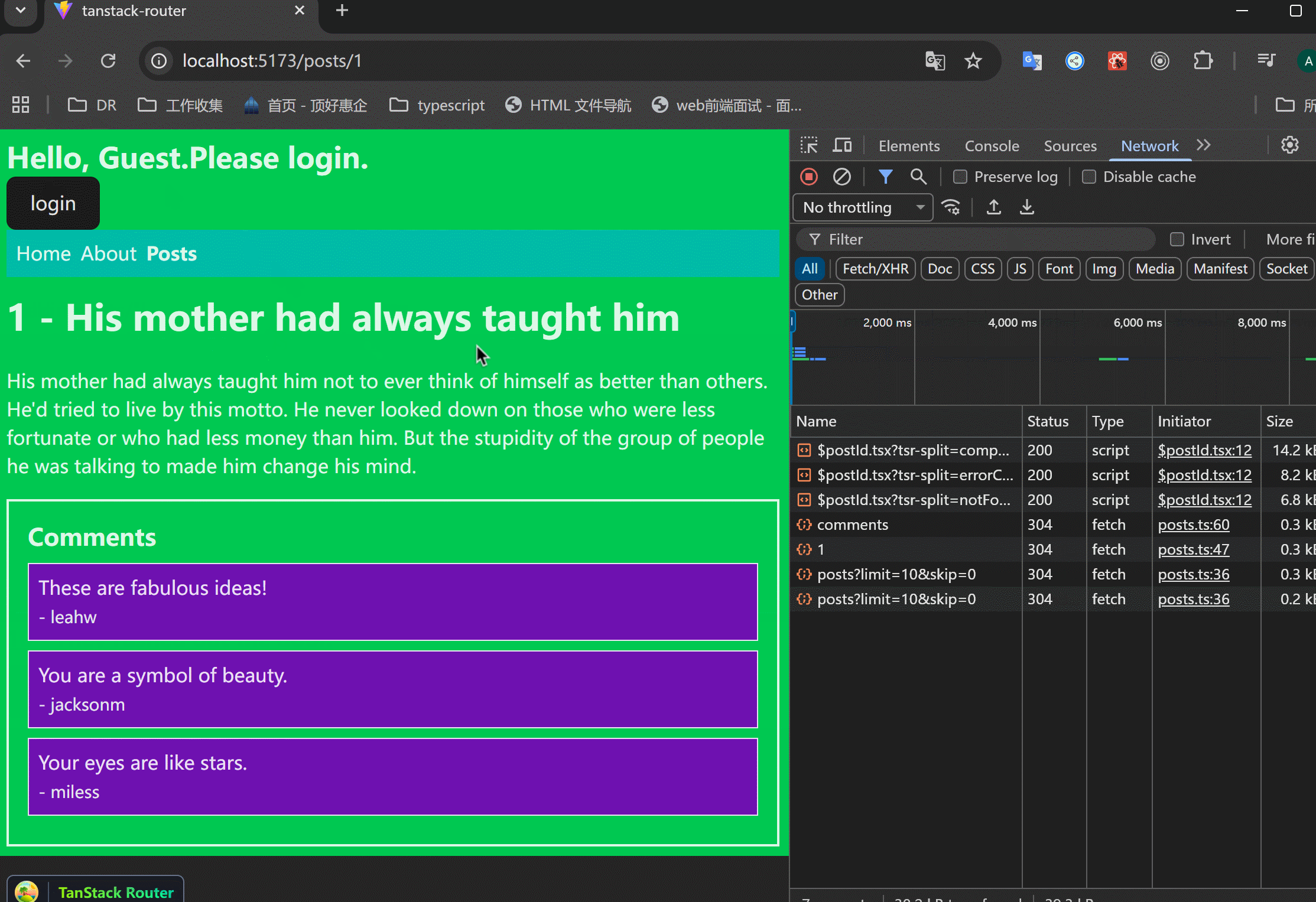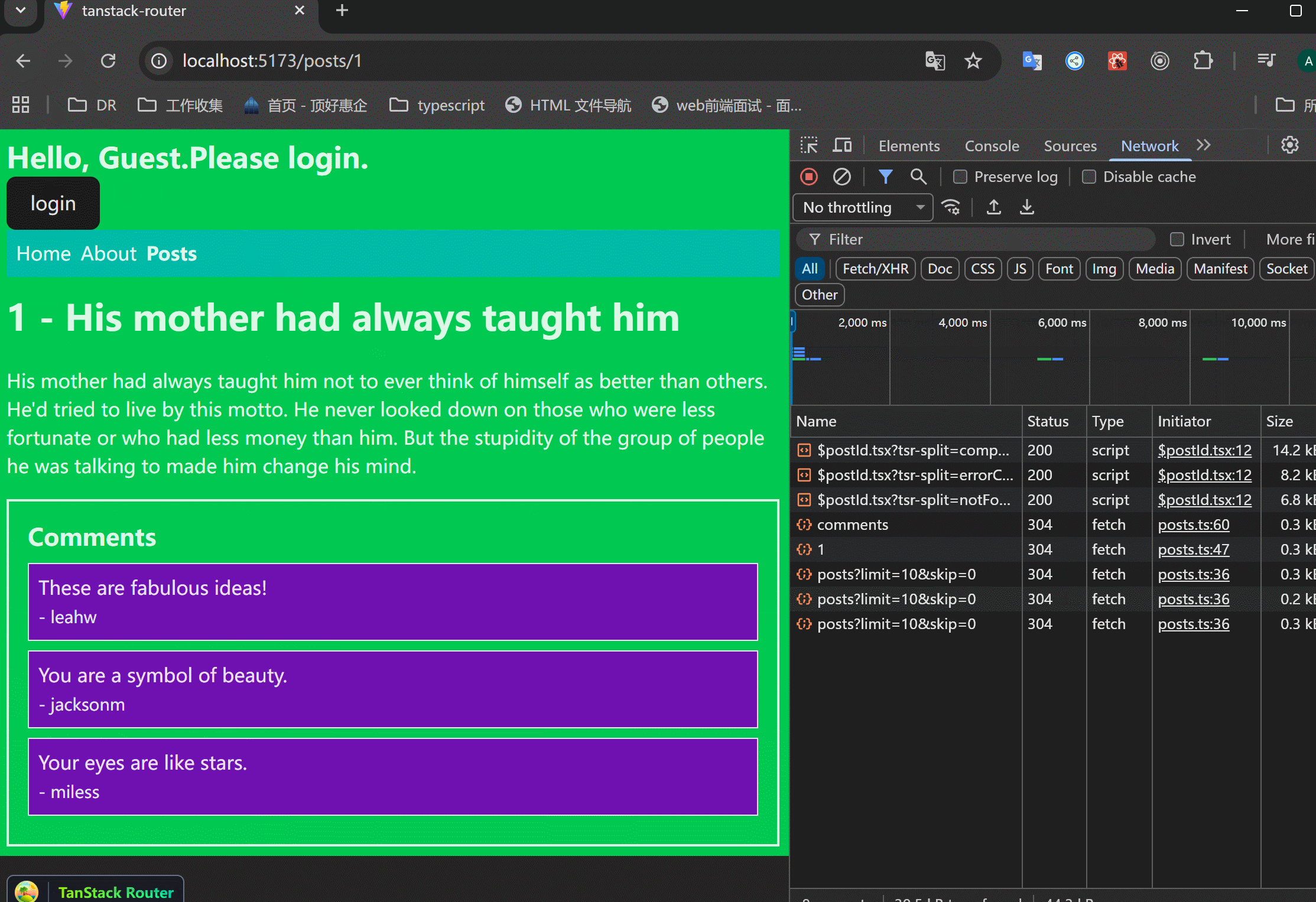
在/posts/$postId页面添加staleTime,看一下缓存:
xxxxxxxxxx11staleTime: 30000,可以看到,进入详情页之后,除了第一次请求了,后面的都是瞬间渲染,这就是缓存的作用。
问题:
如果你同时使用了 TanStack Query,通常建议将路由层的缓存逻辑交给 Query 处理,让 Router 的 loader 仅作为触发器。
这个怎么做?tanstack router不是自带有缓存吗?
确实,TanStack Router 自带缓存机制,但当你引入 TanStack Query (React Query) 时,你会发现两者的功能在“数据存储”和“缓存管理”上是有重叠的。
为了避免“一个数据存两份”以及缓存同步混乱,业界推荐的 “Router + Query 黄金搭档” 模式是:利用 Router 驱动跳转,利用 Query 管理数据。
1. 为什么要“舍弃” Router 缓存?
虽然 Router 能够缓存数据,但 TanStack Query 在数据管理上更专业:
- 自动后台静默刷新:当窗口重新聚焦或网络恢复时,Query 可以自动更新数据,而 Router 缓存通常是静态的。
- 更强大的 Mutation 联动:当你修改(Update)数据后,Query 可以一键让相关缓存失效,UI 自动同步;Router 缓存处理起来相对繁琐。
- 多组件共享:Query 缓存是全局的,不仅路由组件能用,任何深度嵌套的子组件都可以通过
useQuery直接获取,无需层层透传loaderData。2. 具体怎么做?(核心步骤)
第一步:在
loader中仅作为“触发器”不要在
loader里直接fetch数据并返回,而是调用 QueryClient 的ensureQueryData方法。这个方法的作用是:“如果缓存里有新鲜的就直接给路由,没有就去下载并存入 Query 缓存。”xxxxxxxxxx61// postsRoute.tsx2export const Route = createFileRoute('/posts')({3// 将 queryClient 通过 context 传入(在 createRouter 时注入)4loader: ({ context: { queryClient } }) =>5queryClient.ensureQueryData(postsQueryOptions()),6})第二步:在组件中使用
useSuspenseQuery在页面组件里,不要再用
Route.useLoaderData(),而是直接使用 Query 的 Hook。xxxxxxxxxx61function PostsComponent() {2// 因为 loader 已经确保了数据在缓存里,这里会直接秒开3const { data } = useSuspenseQuery(postsQueryOptions())45return <div>{/* 渲染数据 */}</div>6}3. 配置 Router 禁用自带缓存
为了让逻辑完全归于 Query,我们需要在 Router 层做一些“减法”,防止 Router 的缓存机制干扰 Query 的刷新逻辑。
在
createRouter中,建议将staleTime设为0:xxxxxxxxxx101const router = createRouter({2routeTree,3context: { queryClient },4defaultOptions: {5// 让 Router 永远认为它的“路由指向”是旧的6// 这样每次切换路由,Router 都会执行 loader 里的 ensureQueryData7// 进而把控制权交给 TanStack Query8staleTime: 0,9},10})4. 这种模式下的数据流
用户点击链接:Router 匹配到路由。
执行 Loader:调用
queryClient.ensureQueryData。Query 介入:
- Query 检查自己的缓存。
- 如果有数据且未过期(Query 的
staleTime),直接返回。- 如果没有或已过期,发起请求,存入 Query 缓存,然后返回。
渲染组件:组件通过
useSuspenseQuery拿到 Query 缓存中的数据。总结建议
- Router 负责:URL 解析、权限校验 (
beforeLoad)、触发数据获取指令。- Query 负责:数据的持久化、缓存过期逻辑、后台同步、多组件共享。
这样做之后,你的整个应用就拥有了“路由级触发”和“专业级缓存”的双重优势。
Protecting Routes
可以为一个路由单独做protect,也可以为多个路由一起做protect。都是使用 beforeLoad 属性。
在 TanStack Router 中,实现 Protect Route(受保护路由/权限路由) 的标准做法是使用 beforeLoad 属性。
beforeLoad 是路由生命周期中的第一个环节,它运行在 loader 之前。如果校验失败,你可以直接触发重定向或抛出错误,从而阻止用户进入该页面。
1. 核心逻辑实现
最常见的方法是在 RootRoute 或一个 Pathless Route(无路径路由) 中统一处理认证逻辑。
示例:创建一个受保护的布局路由
你可以创建一个名为 _authenticated.tsx 的文件(下划线开头表示不增加 URL 层级),让所有需要登录的页面都作为它的子路由。
xxxxxxxxxx201// routes/_authenticated.tsx2export const Route = createFileRoute('/_authenticated')({3 beforeLoad: ({ context, location }) => {4 // 1. 从 context 中获取认证状态(通常在 createRouter 时注入)5 if (!context.auth.isAuthenticated) {6 // 2. 如果未登录,重定向到登录页7 // redirect 会抛出一个特殊的错误,停止后续 loader 的执行8 throw redirect({9 to: '/login',10 // 传递search参数,方便登录成功后返回原页面11 search: {12 // 告诉登录页:登录成功后跳回现在的页面13 redirect: location.href,14 },15 })16 }17 },18})19202. 在 Router 中注入 Auth 上下文
为了让 beforeLoad 能访问到登录状态,你需要在创建 Router 时通过 context 注入。
xxxxxxxxxx141// router.tsx2const router = createRouter({3 routeTree,4 context: {5 // 注入 auth 对象,可以是来自 useAuth hook 的状态6 auth: undefined!, 7 },8})910// 在 App 组件中传入实时状态11function App() {12 const auth = useAuth()13 return <RouterProvider router={router} context={{ auth }} />14}3. 为什么选择 beforeLoad 而不是在组件内判断?
- 性能更优:在 JS 包下载完、Loader 执行前就完成了拦截,避免了不必要的 API 请求。
- 防止闪烁:如果进入组件后再判断,用户可能会看到一瞬间的受保护内容(Layout 闪烁),
beforeLoad能彻底杜绝这个问题。 - 类型安全:你可以通过 TypeScript 强制要求某些路由必须拥有
auth上下文。
4. 处理更复杂的权限(角色权限)
如果你需要判断用户是否有特定的权限(如:只有管理员能看),逻辑是一样的:
xxxxxxxxxx91// routes/admin.tsx2export const Route = createFileRoute('/admin')({3 beforeLoad: ({ context }) => {4 const user = context.auth.user5 if (user?.role !== 'admin') {6 throw redirect({ to: '/unauthorized' })7 }8 },9})5. 关于 redirect 的注意事项
- 在
beforeLoad中使用:必须使用throw redirect(...)。 - 在组件中使用:通常使用
useNavigate或<Navigate />组件,不要在渲染逻辑中throw redirect。
总结
- 全局拦截:在
RootRoute或 Pathless Route 的beforeLoad中处理。 - 数据隔离:确保
context实时同步最新的认证状态。 - 用户体验:利用
search参数保存redirect路径,登录后实现自动回跳。
老师案例
这节课先学习为单个文件设置拦截。
假设我们跳转到/about页面,需要先检查是否登录了,如果没有登录,则跳转到/login页面。
1、为/about页面设置拦截
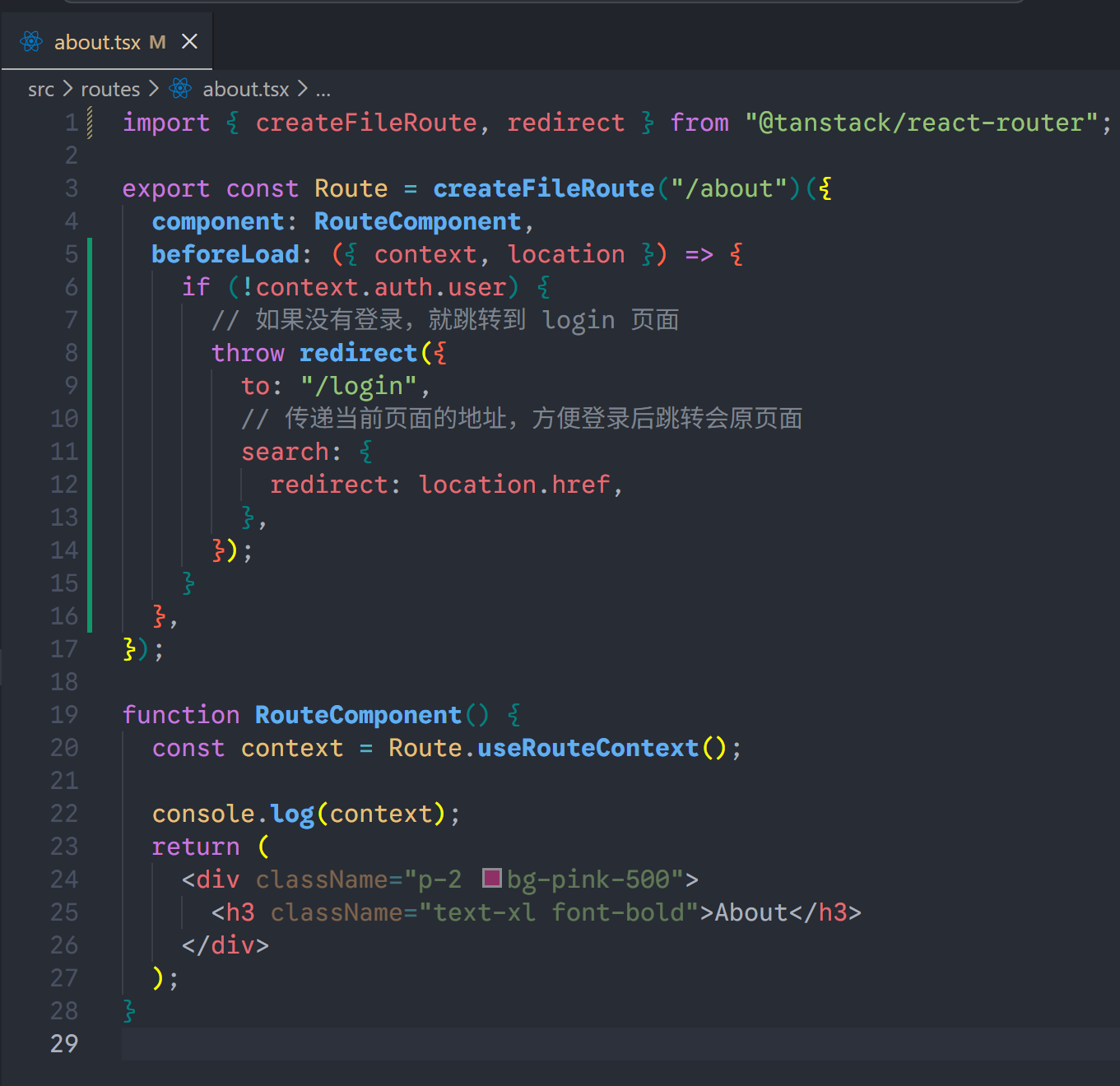
2、创建login页面,处理登录逻辑
xxxxxxxxxx521// src/routes/login.tsx23import { createFileRoute, redirect } from "@tanstack/react-router";4import { zodValidator } from "@tanstack/zod-adapter";5import z from "zod";67// search 参数校验8const loginSearchParamsSchema = z.object({9 redirect: z.string().optional(),10});1112export const Route = createFileRoute("/login")({13 component: RouteComponent,14 validateSearch: zodValidator(loginSearchParamsSchema),15 beforeLoad: ({ context, search }) => {16 // 当上下文里面有user的时候,如果访问 /login 页面,就重定向到原页面,避免重复登录。17 if (context.auth.user) {18 throw redirect({19 to: search.redirect || "/",20 });21 }22 },23});2425function RouteComponent() {26 const {27 auth: { login },28 } = Route.useRouteContext();2930 // 接收传递过来的search参数31 const { redirect } = Route.useSearch();32 const navigate = Route.useNavigate();3334 return (35 <div>36 Hello "/login"! <br />{" "}37 <button38 onClick={() => {39 login({40 id: 1,41 name: "jack",42 });43 // 登录成功后,返回原页面44 navigate({45 to: redirect || "/",46 });47 }}>48 login49 </button>{" "}50 </div>51 );52}可以看到,访问 /about 如果没有登录,就跳转到 /login 页面,登录之后返回原页面。
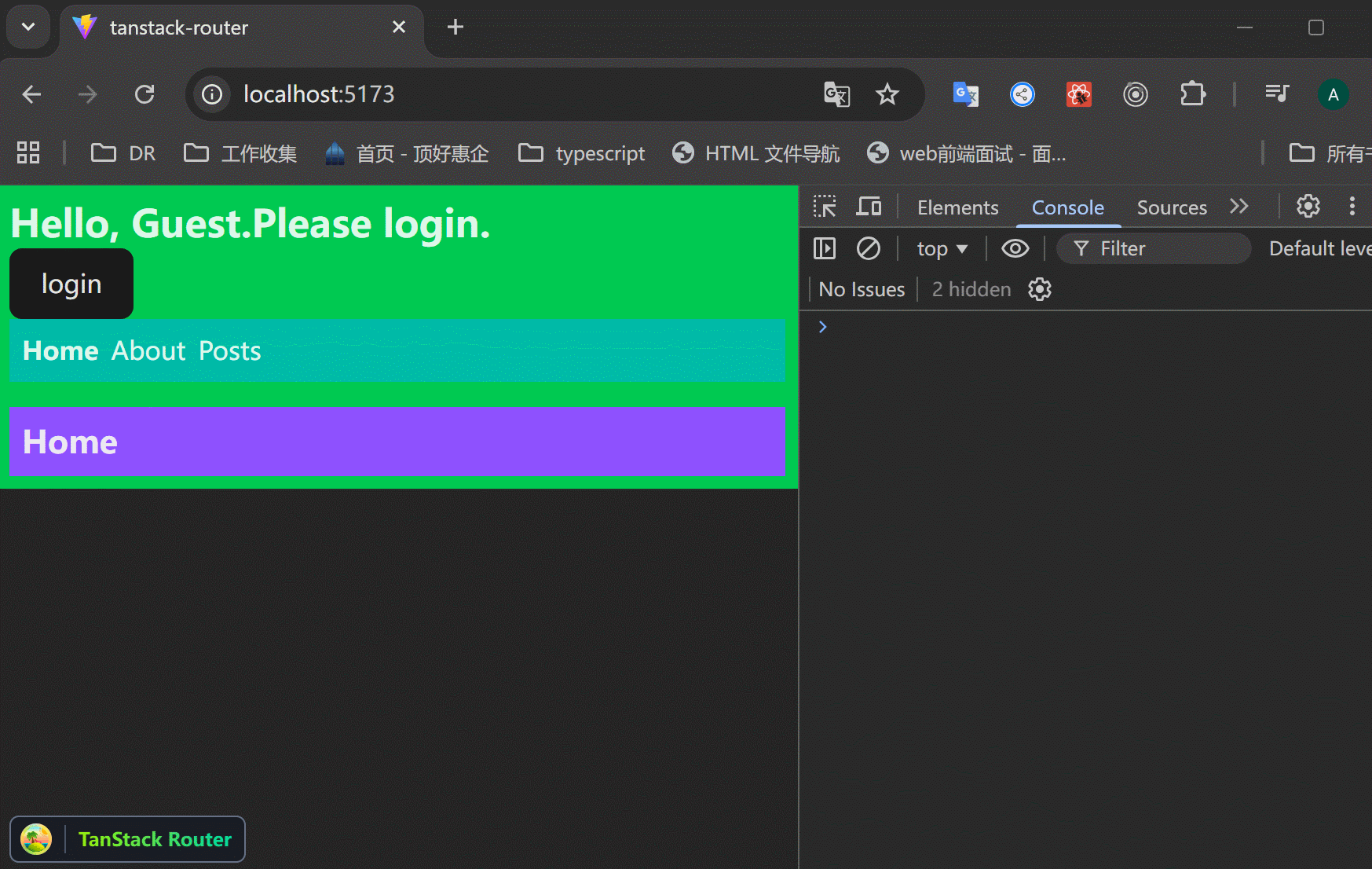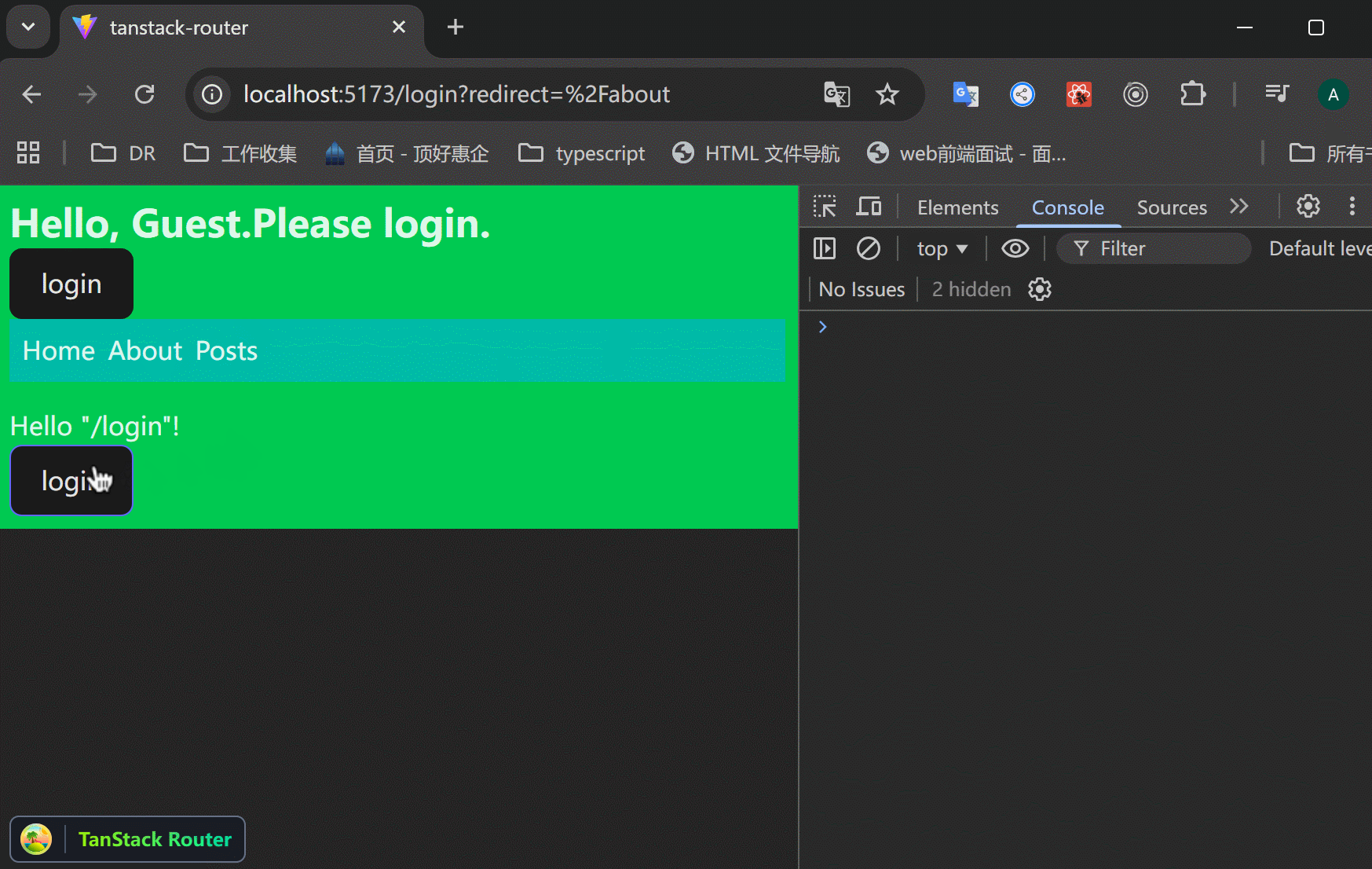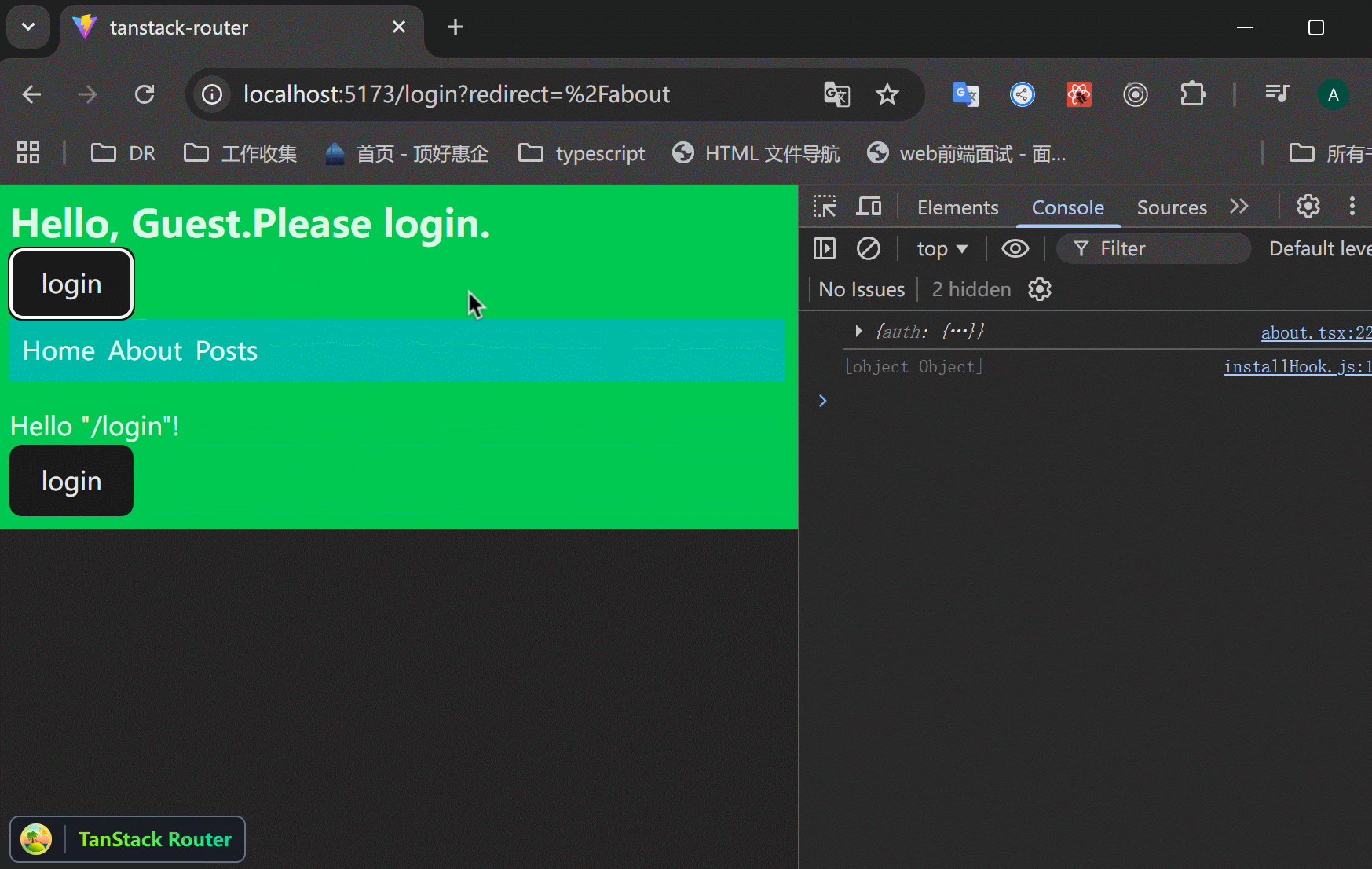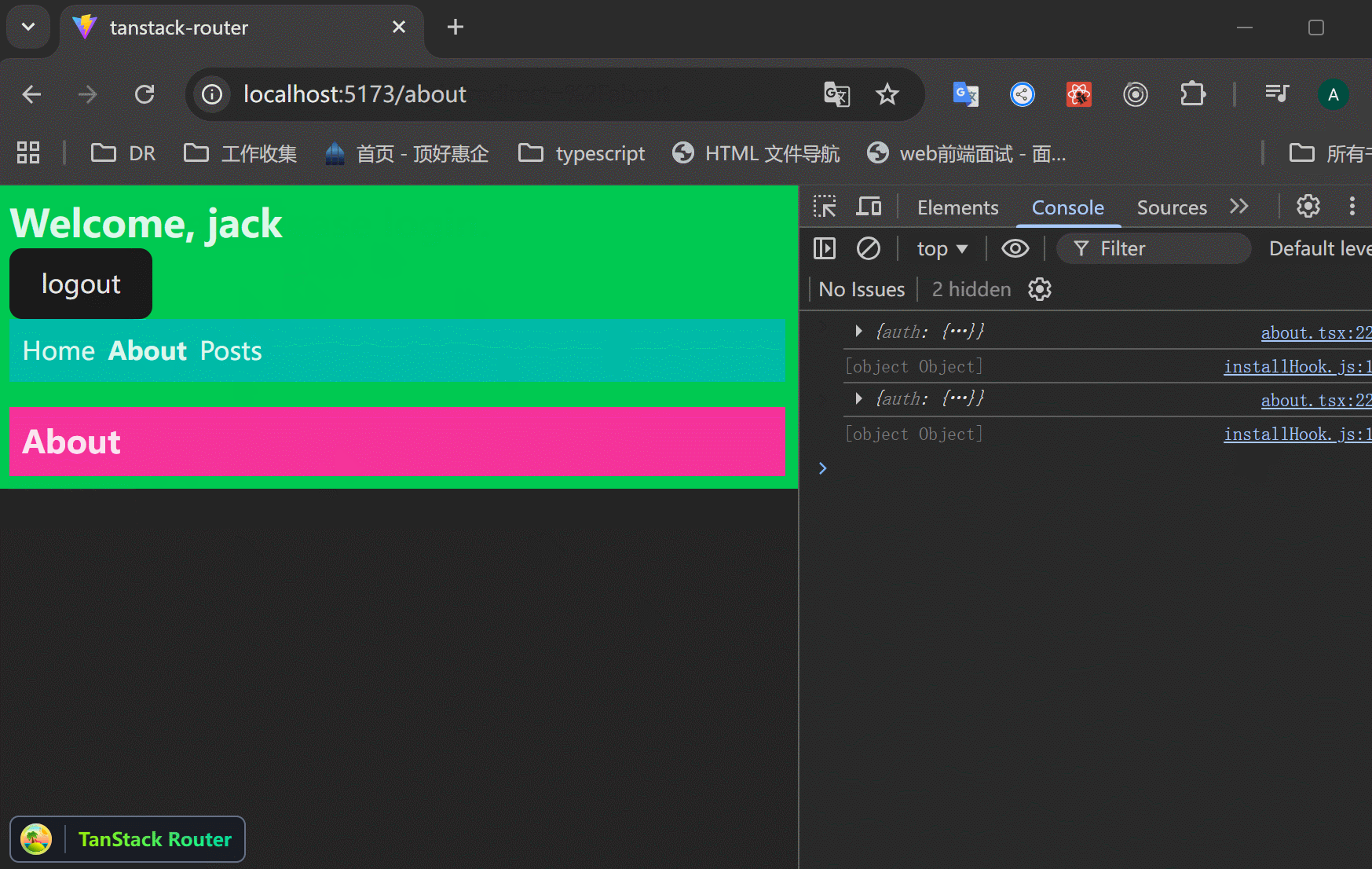
问题:登录成功之后,返回 /about 页面,但是一刷新,就又跳转到 /login 页面了,context里面明明存了数据的啊?
核心原因在于:TanStack Router 的 context 是内存中的临时状态,页面刷新后全部丢失。
1、context.auth.user 的来源
xxxxxxxxxx51beforeLoad: ({ context, search }) => {2if (context.auth.user) { // ← 这里检查的是 context 里的 user3throw redirect({ to: search.redirect || "/" });4}5}这个 context.auth.user 是每次路由渲染时从 <RouterProvider context={{ auth }}> 注入的。
2、页面刷新时发生了什么?
- 浏览器重新加载整个应用 → React 重新 mount
- useState、useReducer 等所有状态全部重置为初始值
- 你的 auth 状态(不管是 useState 还是 Context Provider 里的)都会回到初始值:user = null
- 于是 <RouterProvider context={{ auth: { user: null, ... } }}> 注入的 context 也是 user: null
- 访问 /about → beforeLoad 检查 context.auth.user 为 null → 重定向到 /login
3、一句话总结:刷新 = 内存清空 = 登录状态丢失 = 又被踢回登录页
你看到的“明明有数据”只是假象 在不刷新的情况下(点击登录按钮 → login() → setUser(...) → invalidate()),context 确实更新了,页面能正常跳转到 /about。但一刷新,setUser 做的所有状态就没了。
解决办法:
方案 1:最简单(开发/学习阶段) - 使用 localStorage
xxxxxxxxxx201// AuthProvider.tsx 或类似地方2function AuthProvider({ children }) {3const [user, setUser] = useState<User | null>(() => {4// 页面加载时尝试从 localStorage 恢复5const saved = localStorage.getItem('user');6return saved ? JSON.parse(saved) : null;7});89const login = (newUser: User) => {10setUser(newUser);11localStorage.setItem('user', JSON.stringify(newUser));12};1314const logout = () => {15setUser(null);16localStorage.removeItem('user');17};1819// ... 其他代码20}方案 2:更安全(生产环境) - 使用 HttpOnly cookie + token
- 登录时,后端返回 token,并设置 HttpOnly cookie
- 前端通过 API 请求(带 cookie)获取当前用户信息
- 在应用启动时(比如 App 根组件)调用一个 checkAuth API 来恢复 user
xxxxxxxxxx121// App.tsx 或根组件2useEffect(() => {3const checkAuth = async () => {4try {5const response = await api.get('/me'); // 带 cookie 的请求6setUser(response.data.user);7} catch {8setUser(null);9}10};11checkAuth();12}, []);然后 beforeLoad 里检查的就是这个恢复后的 user。
Protecting Multiple Routes with Layouts
这节课学习为多个路由设置拦截。
之前学习过Pathless Layouts,无路由路径。意思就是:

因此,我们可以将需要拦截的路由,全部放到这个路径下面,在这个文件里面编写beforeLoad拦截。
1、创建一个_authenticated.tsx文件
xxxxxxxxxx211// src/routes/_authenticated.tsx23import { createFileRoute, Outlet, redirect } from "@tanstack/react-router";45export const Route = createFileRoute("/_authenticated")({6 component: RouteComponent,7 beforeLoad: ({ context, location }) => {8 if (!context.auth.user) {9 throw redirect({10 to: "/login",11 search: {12 redirect: location.href,13 },14 });15 }16 },17});1819function RouteComponent() {20 return <Outlet />;21}2、在_authenticated底下创建路由文件,这样这些路由都会得到拦截
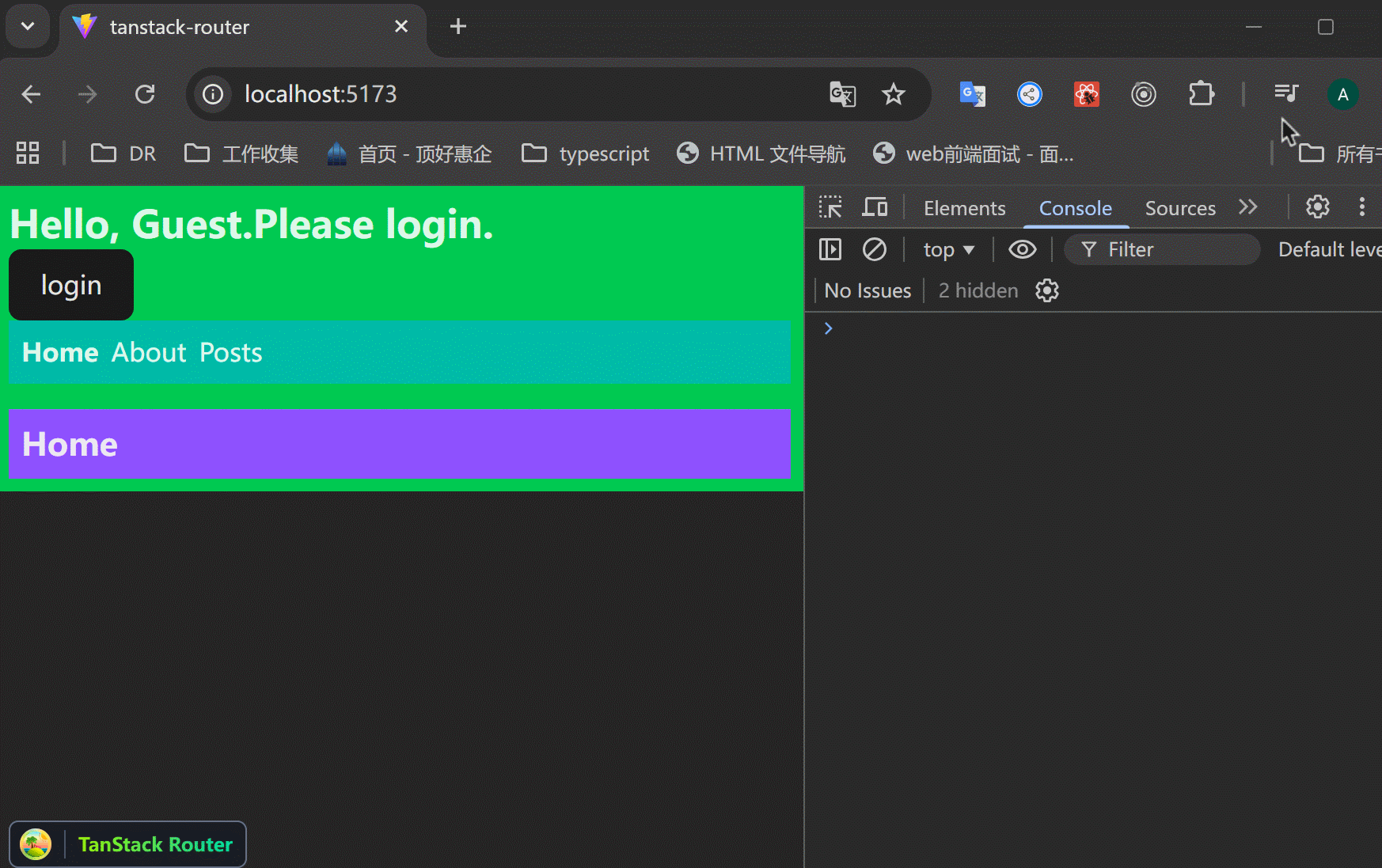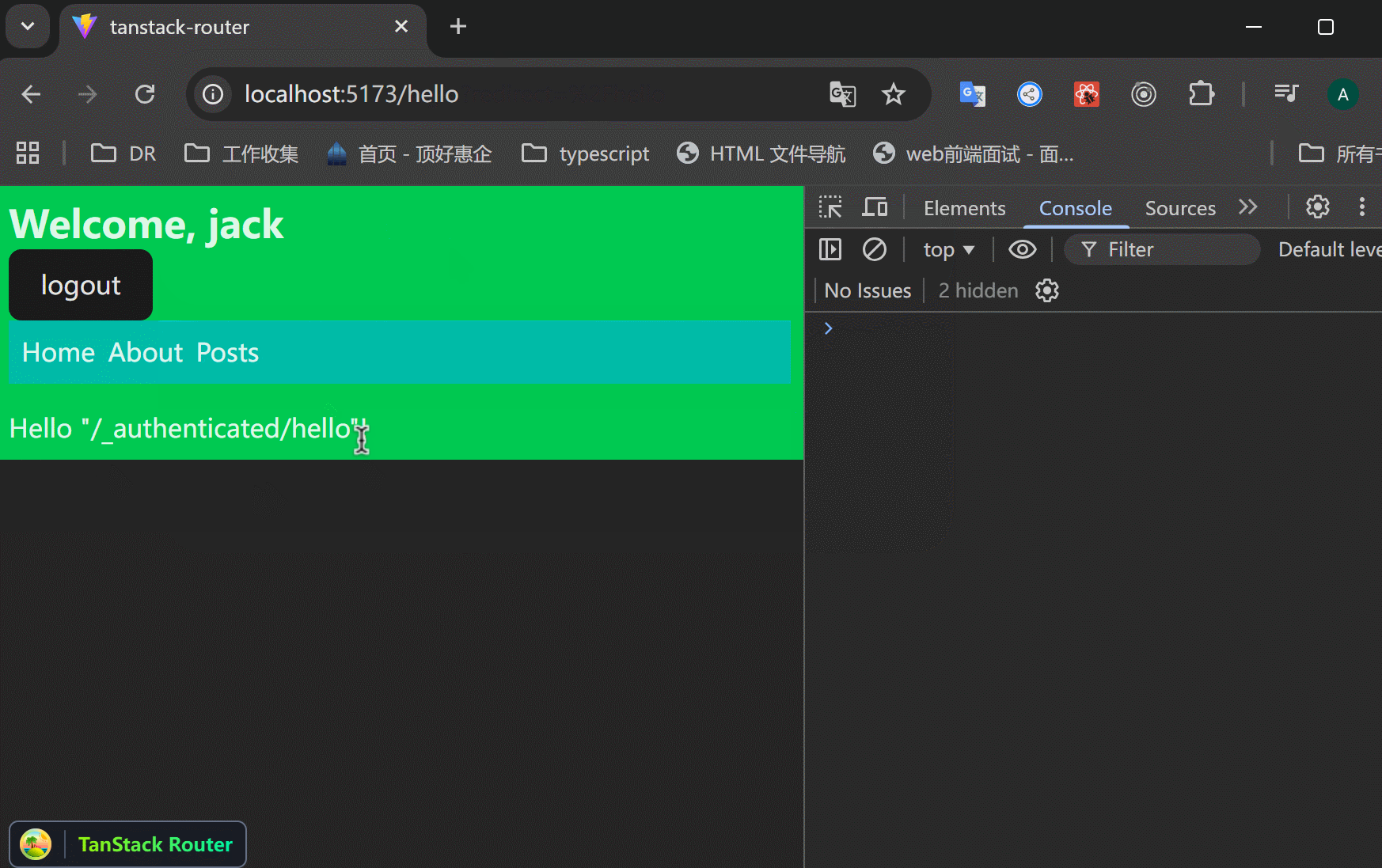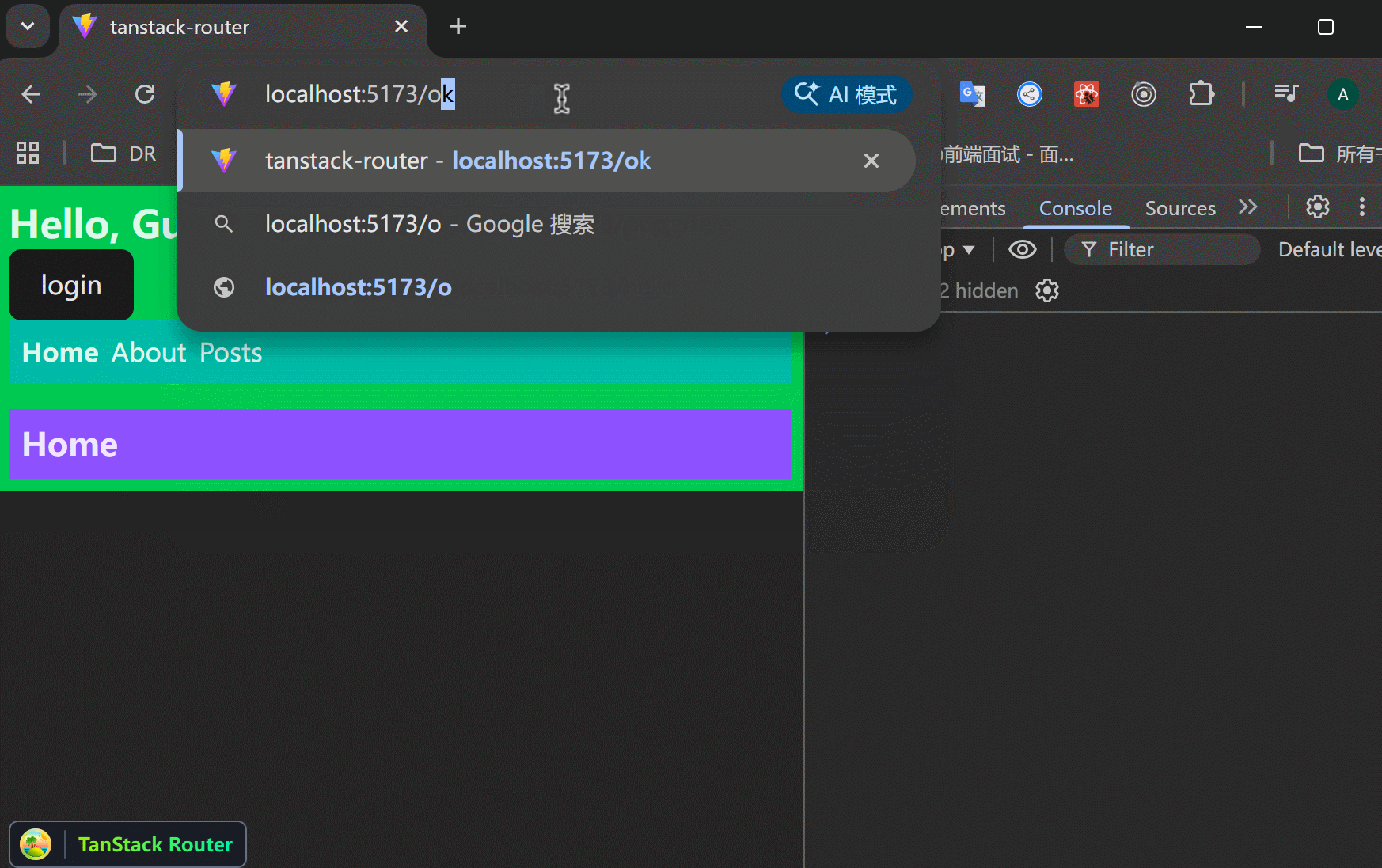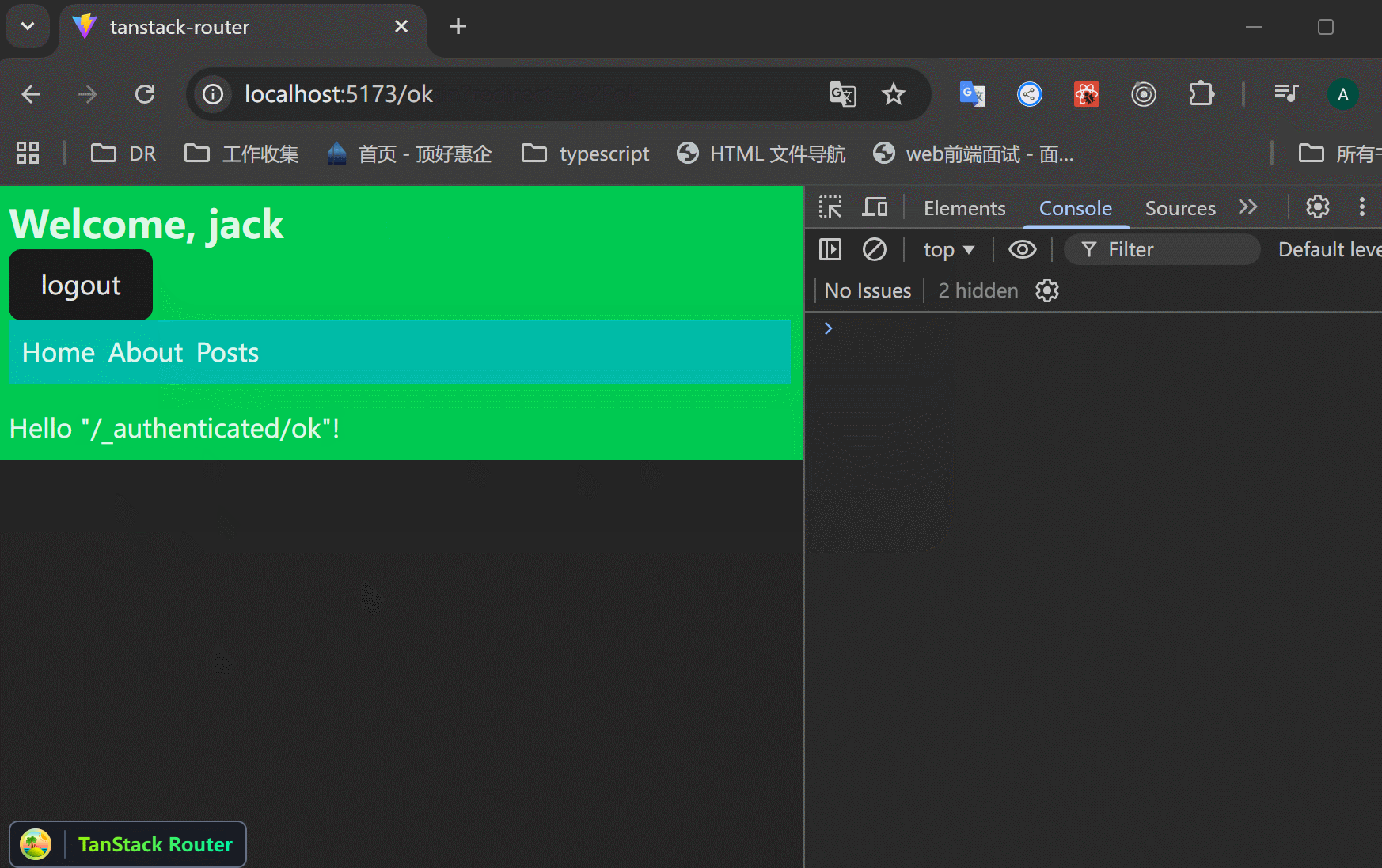
xxxxxxxxxx111// src/routes/_authenticated.hello.tsx23import { createFileRoute } from '@tanstack/react-router'45export const Route = createFileRoute('/_authenticated/hello')({6 component: RouteComponent,7})89function RouteComponent() {10 return <div>Hello "/_authenticated/hello"!</div>11}类似的,还可以创建很多。
可以看到,_authenticated底下的路由,不用在自己的文件代码里面写beforeLoad了,而且都受到保护了。一次性搞定。
不直接跳转,让用户点击按钮跳转
有时候会觉得直接跳转的用户体验不好,可以先显示一些信息,然后用户点击按钮跳转到登录页面。
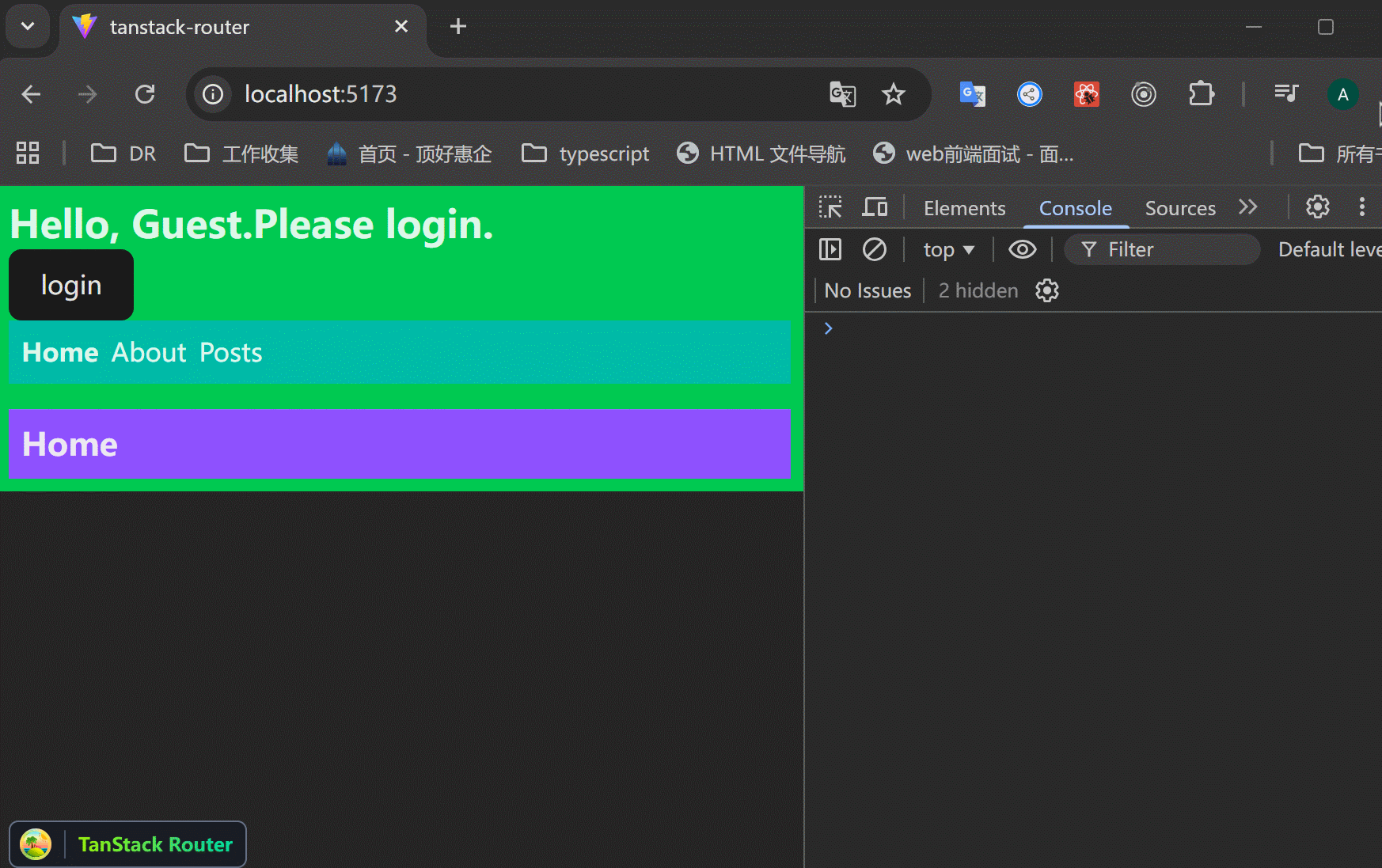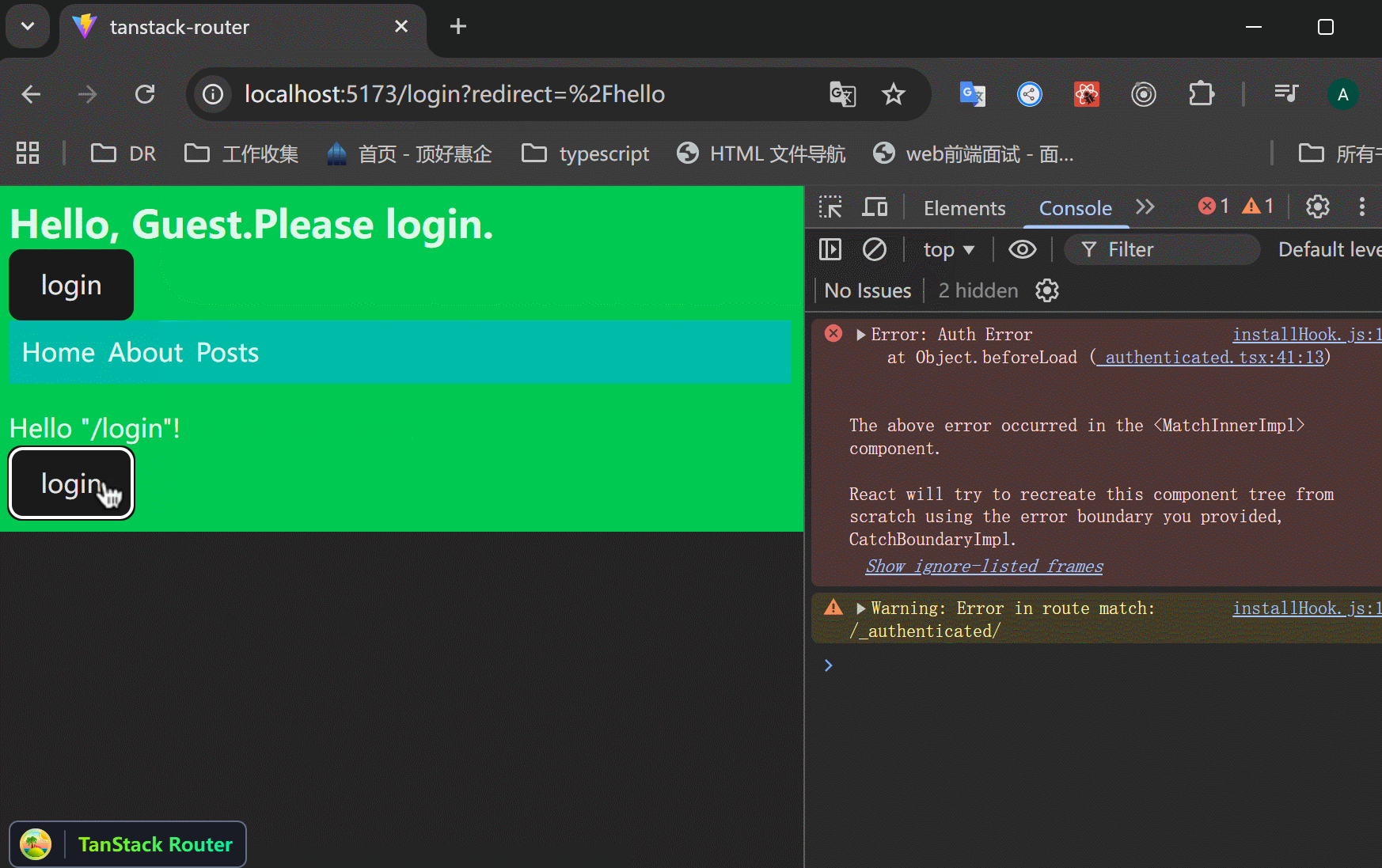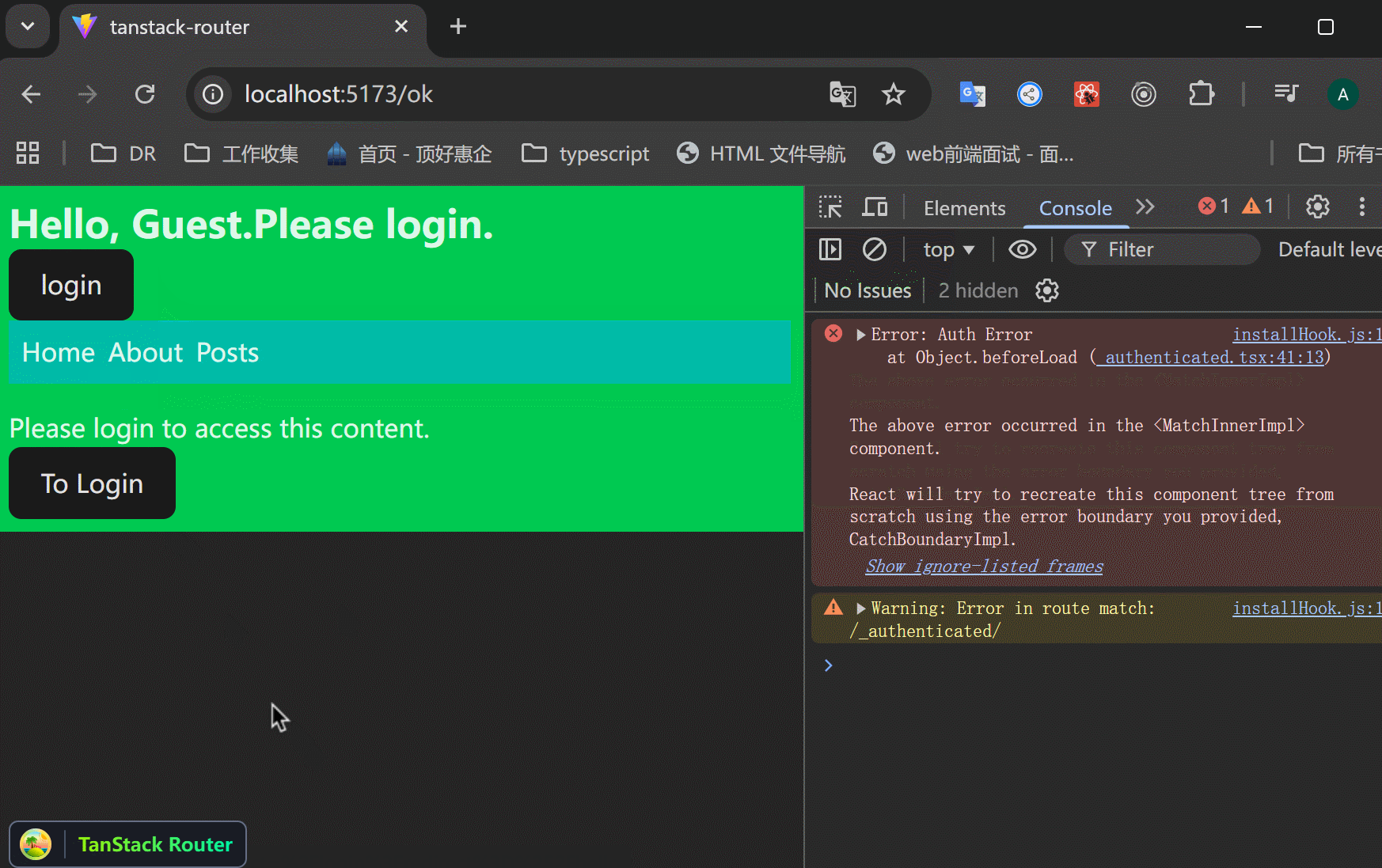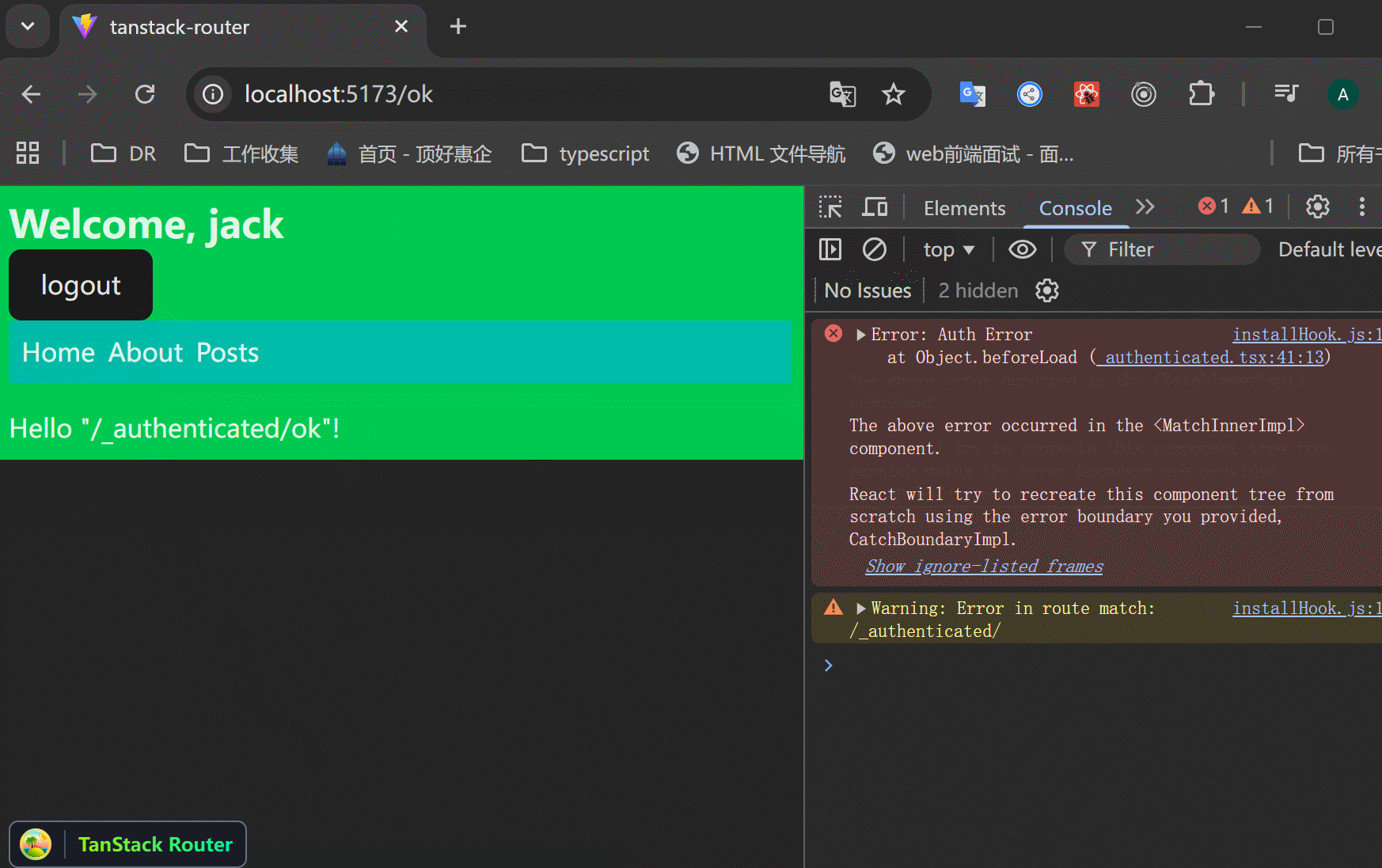
xxxxxxxxxx401// src/routes/_authenticated.tsx23import {4 createFileRoute,5 Link,6 Outlet,7 useLocation,8} from "@tanstack/react-router";910function AuthRoute() {11 const location = useLocation();1213 return (14 <div>15 <h3>Please login to access this content.</h3>16 <Link17 to="/login"18 search={{19 redirect: location.href,20 }}>21 <button>To Login</button>22 </Link>23 </div>24 );25}2627export const Route = createFileRoute("/_authenticated")({28 component: RouteComponent,29 beforeLoad: ({ context }) => {30 if (!context.auth.user) {31 // 抛出一个错误,从而显示errorComponent。32 throw new Error("Auth Error");33 }34 },35 errorComponent: () => <AuthRoute />,36});3738function RouteComponent() {39 return <Outlet />;40}可以看到,不是直接跳转到login页面,而是先展示一些信息,让用户自己跳转到login页面。登录后返回原页面。
getRouteApi
getRouteApi 是 TanStack Router 中一个非常实用、类型安全的工具函数,它的主要作用是:让你在任意组件(甚至非路由组件)中,以强类型的方式访问特定路由的 API(包括 params、search、loader data、context 等),而不需要依赖 useParams、useSearch、useLoaderData 等 hook。
简单来说,它相当于“路由专属的类型安全 hook 生成器”。
核心作用总结
getRouteApi(routeId) → 返回一个对象,里面包含一系列类型安全的 hook 和工具函数,这些 hook 只针对指定的路由有效。
它返回什么?(常用成员)
xxxxxxxxxx131const api = getRouteApi('/posts/$postId') // 传入路由的 ID(通常是路径)23api 包含以下成员:45- useParams() // 只返回这个路由的 params,且类型精确6- useSearch() // 只返回这个路由的 search params7- useLoaderData() // 只返回这个路由的 loader 返回值8- useRouteContext() // 只返回这个路由及其父路由累积的 context9- useNavigate() // 跳转时自动带上当前路由的上下文10- useMatch() // 获取匹配信息11- useMatches() // 获取所有匹配的路由栈12- useParentMatches() // 父路由匹配栈13- useChildMatches() // 子路由匹配栈(如果有)典型使用场景对比(为什么需要它)
| 场景描述 | 不用 getRouteApi 的写法 | 用 getRouteApi 的写法 | 优势 |
|---|---|---|---|
| 在子组件里获取 posts 详情页的 postId | const { postId } = Route.useParams() | const { postId } = api.useParams() | 类型安全,IDE 提示精确 |
| 在非路由组件里用 loader 数据 | 只能传 props,或者用全局 context | const data = api.useLoaderData() | 直接拿,不用层层 props |
| 组件复用在多个路由,但想针对不同路由取不同数据 | 很难做类型安全 | 每个路由用不同的 getRouteApi | 强类型隔离 |
| 写一个只在 /posts/$postId 下才渲染的组件 | 写死 useParams 容易出错 | 用 api.useParams(),编译期就知道必须有 postId | 防呆 |
| 在深层嵌套组件里访问父路由的 context | 层层 useRouteContext() + 类型断言 | api.useRouteContext() 直接拿 | 干净 + 类型安全 |
真实代码例子(最常见的几种用法)
xxxxxxxxxx331// 1. 在任意深层组件中使用(无需 props 透传,也无需上下文)2import { getRouteApi } from '@tanstack/react-router'34const postRouteApi = getRouteApi('/posts/$postId')56function PostTitle() {7 // 类型: { postId: string }8 const { postId } = postRouteApi.useParams()910 // 类型:你 loader 返回的类型11 const { post } = postRouteApi.useLoaderData()1213 return <h1>{post.title} (ID: {postId})</h1>14}1516// 2. 组件只在特定路由下渲染时强制类型17function CommentList() {18 const { comments } = postRouteApi.useLoaderData() // 编译期就知道有 comments19 // ...20}2122// 3. 与 useNavigate 结合(自动推导跳转类型)23function BackButton() {24 const navigate = postRouteApi.useNavigate()2526 return (27 <button28 onClick={() => navigate({ to: '..' })} // 自动知道 .. 是 /posts29 >30 返回列表31 </button>32 )33}什么时候最应该用 getRouteApi?
- 组件层级很深,不想层层透传数据
- 想写可复用组件,但只在某个特定路由下使用
- 需要强类型安全(尤其大型项目,几十个路由时)
- 想避免 any 或类型断言
- 写 utility 组件 / hooks 时,想绑定特定路由
简单记口诀:
“组件深了用 props 烦?用 getRouteApi 直接戳路由!”
More Topics & Outro
还有很多概念需要了解一下,比如说:Route Masking、Navigation Blocking、SSR、Type Utilities。